
New Ryzen AI 9 HX 370 machine
I have a new AMD performance machine for experiments. The processor is a Ryzen AI 9 HX 370 in a Beelink SER9 mini-PC.
Following are some of the major parameters.in comparison with my Ryzen 7840HS comparison machine.
| Item | Ryzen 7840HS | Ryzen AI 9 HX 370 | Notes |
|---|---|---|---|
| Architecture | Zen4 | Zen 5 | |
| Cores | 8 | 12 (4x Zen 5 and 8x Zen 5c) | |
| Threads | 16 | 24 | |
| Base Clock | 3.8 GHz | 2.0 GHz, 2.0 GHz | |
| Boost Clock | 5.1 GHz | 5.1 GHz, 3.3 GHz | |
| TDP | 35-45W | 15-54W | Set by vendor |
| Memory | 32 GB (2 x 16 GiB) DDR5 – 5600 2 Memory Channels | 32 GB (4x 8 GiB) DDR5 – 7500 2 Memory Channels | Check BIOS for actual speed |
| Stream | Copy: 71400 MB/s Scale: 70300 MB/s Add: 73600 MB/s Triad: 73000 MB/s | Copy: 86725 MB/s Scale: 86626 MS/s Add: 88192 MB/s Triad: 87655 MB/s | Measured |
| Cache | L1 – 32kB, 8 way, 4 clocks L2 – 1 MB, 8-way, 14 clocks L3 – 16MB, 24 way, 47 clocks | L1 – 32kB L2 – 1 MB L3 – 24 MB | Agner Fog architecture document and likwid-topology |
| lmbench | L1 – 0.8 ns L2 – 3 ns L3 – 8 ns | L1 – 0.8 ns L2 – 3ns L3 – 8 ns | Measured in Nanoseconds |
| Graphics | Radeon 780M 12 cores 2700 MHz | Radeon 890M 16 cores 2900 MHz | |
| Phoronix stream | Average: 40604 MB/s | Average 44500 MB/s | |
| Phoronix coremark | Average 464076 Iterations/second | Average 563477 Iterations/second | +21% |
Following are the results from likwid-topology. This is a hybrid core with four Zen5 cores and eight Zen5c cores. I believe the first four cores are Zen5 and the remaining eight are Zen5c.
--------------------------------------------------------------------------------
CPU name: AMD Ryzen AI 9 HX 370 w/ Radeon 890M
CPU type: nil
CPU stepping: 0
********************************************************************************
Hardware Thread Topology
********************************************************************************
Sockets: 1
Cores per socket: 12
Threads per core: 2
--------------------------------------------------------------------------------
HWThread Thread Core Die Socket Available
0 0 0 0 0 *
1 0 1 0 0 *
2 0 2 0 0 *
3 0 3 0 0 *
4 0 4 0 0 *
5 0 5 0 0 *
6 0 6 0 0 *
7 0 7 0 0 *
8 0 8 0 0 *
9 0 9 0 0 *
10 0 10 0 0 *
11 0 11 0 0 *
12 1 0 0 0 *
13 1 1 0 0 *
14 1 2 0 0 *
15 1 3 0 0 *
16 1 4 0 0 *
17 1 5 0 0 *
18 1 6 0 0 *
19 1 7 0 0 *
20 1 8 0 0 *
21 1 9 0 0 *
22 1 10 0 0 *
23 1 11 0 0 *
--------------------------------------------------------------------------------
Socket 0: ( 0 12 1 13 2 14 3 15 4 16 5 17 6 18 7 19 8 20 9 21 10 22 11 23 )
--------------------------------------------------------------------------------
********************************************************************************
Cache Topology
********************************************************************************
Level: 1
Size: 48 kB
Cache groups: ( 0 12 ) ( 1 13 ) ( 2 14 ) ( 3 15 ) ( 4 16 ) ( 5 17 ) ( 6 18 ) ( 7 19 ) ( 8 20 ) ( 9 21 ) ( 10 22 ) ( 11 23 )
--------------------------------------------------------------------------------
Level: 2
Size: 1 MB
Cache groups: ( 0 12 ) ( 1 13 ) ( 2 14 ) ( 3 15 ) ( 4 16 ) ( 5 17 ) ( 6 18 ) ( 7 19 ) ( 8 20 ) ( 9 21 ) ( 10 22 ) ( 11 23 )
--------------------------------------------------------------------------------
Level: 3
Size: 16 MB
Cache groups: ( 0 12 1 13 2 14 3 15 ) ( 4 16 5 17 6 18 7 19 ) ( 8 20 9 21 10 22 11 23 )
--------------------------------------------------------------------------------
********************************************************************************
NUMA Topology
********************************************************************************
NUMA domains: 1
--------------------------------------------------------------------------------
Domain: 0
Processors: ( 0 12 1 13 2 14 3 15 4 16 5 17 6 18 7 19 8 20 9 21 10 22 11 23 )
Distances: 10
Free memory: 22667.5 MB
Total memory: 27574.2 MB
--------------------------------------------------------------------------------
The L3 cache amount may be incorrect as specifications suggest 24 MB of cache. Using lmbench suggests the L3 cache attached to first four cores is 16MB and the next groups have 8MB likely together even though topology above makes them separate.
This hybrid SOC shows up in the following coremark scaling comparison as shown in the graph below. There are several different regions
- From 1 to 4 cores we compare Zen4 cores against Zen5 cores. The coremark value for 4 cores is ~12% ahead.
- From 5 to 8 cores, we now have Zen5 + Zen5C cores against Zen4 cores. The coremark value for 8 cores is ~7% behind
- From 9 to 12 cores, we use all the cores on HX 370 and start using SMT for the 7840. The coremark value for 12 cores is 6% ahead
- From 13 to 16 cores we go to using SMT for all the Zen5 cores and not-SMT for Zen5C cores. The 7840 moves to fully SMT. The coremark value for 16 cores is 11% ahead
- From 17 to 24 cores, we go to adding SMT for Zen5C cores. The overall coremark using all cores (24 vs 16) is 21% ahead.
This suggests for coremark and other workloads there will be different regions where combinations of SMT and Zen5 vs Zen5C cores will create interesting comparisons between the systems.
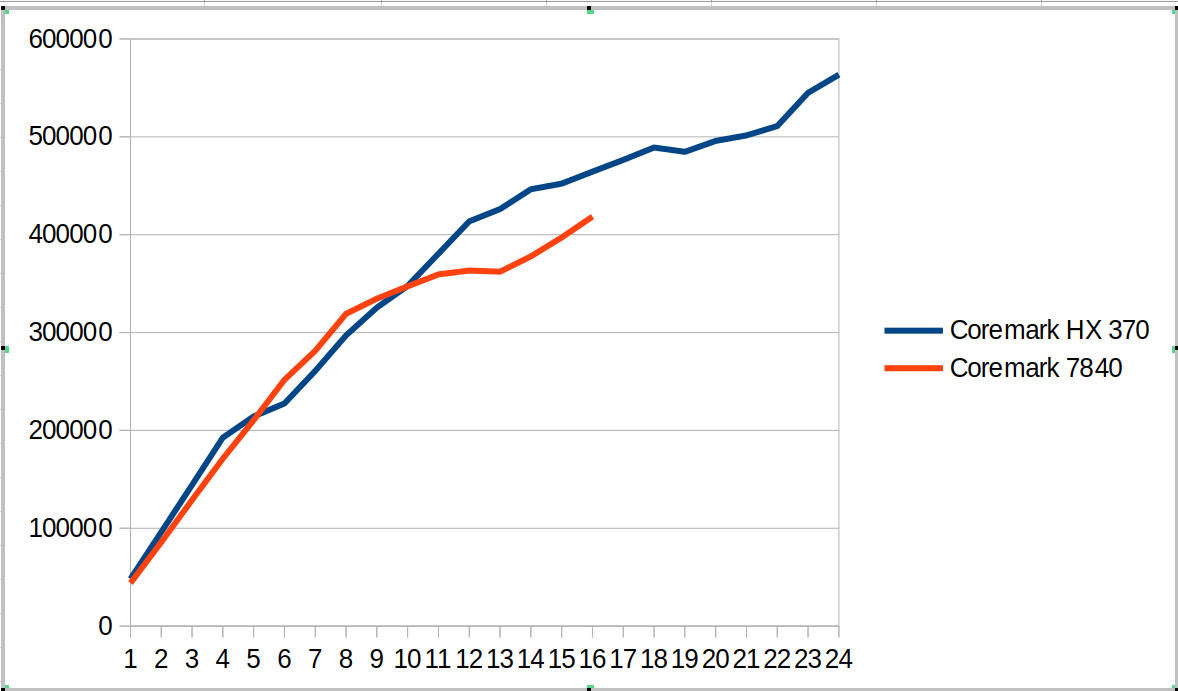
The tabular version of coremark including performance counters is shown below.
| Cores | Coremark HX 370 | Coremark 7840 | Scaling HX 370 | Scaling 7840 | Retiring HX 370 | Frontend HX 370 | Backend HX 370 | Speculation HX 370 | SMT-contention HX 370 | Retiring 7840 | Frontend 7840 | Backend 7840 | Speculation 7840 | SMT-contention 7840 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 48245 | 43881 | 100% | 100% | 44.2% | 25.2% | 62.0% | 2.0% | 0.0% | 43.9% | 12.4% | 43.0% | 0.7% | 0.0% |
| 2 | 96106 | 85758 | 100% | 98% | 44.0% | 25.5% | 61.8% | 2.0% | 0.0% | 43.9% | 12.4% | 43.1% | 0.7% | 0.0% |
| 3 | 144147 | 128841 | 100% | 98% | 44.0% | 25.5% | 61.8% | 2.0% | 0.0% | 43.6% | 13.0% | 42.7% | 0.7% | 0.0% |
| 4 | 192537 | 171061 | 100% | 97% | 44.1% | 25.4% | 61.9% | 2.0% | 0.0% | 43.9% | 12.3% | 43.1% | 0.7% | 0.0% |
| 5 | 214223 | 210368 | 89% | 96% | 44.0% | 25.5% | 61.8% | 2.0% | 0.0% | 43.9% | 12.3% | 43.1% | 0.7% | 0.0% |
| 6 | 227532 | 251705 | 79% | 96% | 44.0% | 25.4% | 61.9% | 2.0% | 0.0% | 43.2% | 12.9% | 43.2% | 0.7% | 0.0% |
| 7 | 260811 | 281369 | 77% | 92% | 44.0% | 25.7% | 61.7% | 2.0% | 0.0% | 43.3% | 12.2% | 43.7% | 0.7% | 0.0% |
| 8 | 297002 | 319098 | 77% | 91% | 44.1% | 25.3% | 61.9% | 2.0% | 0.0% | 42.7% | 12.8% | 43.8% | 0.7% | 0.0% |
| 9 | 325417 | 334602 | 75% | 85% | 44.1% | 25.3% | 62.0% | 2.0% | 0.0% | 40.2% | 15.9% | 36.3% | 0.6% | 7.1% |
| 10 | 347636 | 347246 | 72% | 79% | 44.0% | 25.3% | 61.9% | 2.0% | 0.0% | 38.4% | 17.8% | 30.2% | 0.5% | 13.1% |
| 11 | 380587 | 359402 | 72% | 74% | 44.0% | 25.5% | 61.8% | 2.0% | 0.0% | 36.9% | 19.6% | 25.3% | 0.5% | 17.8% |
| 12 | 413575 | 363288 | 71% | 69% | 44.0% | 25.4% | 61.9% | 2.0% | 0.0% | 35.5% | 21.1% | 21.6% | 0.4% | 21.3% |
| 13 | 426123 | 362144 | 68% | 63% | 42.1% | 28.2% | 52.9% | 1.8% | 8.3% | 34.4% | 22.4% | 18.5% | 0.4% | 24.3% |
| 14 | 446379 | 377767 | 66% | 61% | 40.5% | 30.6% | 45.6% | 1.6% | 15.1% | 33.1% | 24.4% | 15.2% | 0.4% | 26.9% |
| 15 | 452134 | 397145 | 62% | 60% | 39.5% | 32.2% | 40.6% | 1.4% | 19.7% | 32.2% | 25.3% | 12.0% | 0.3% | 30.2% |
| 16 | 464431 | 418462 | 60% | 60% | 38.3% | 33.7% | 35.8% | 1.3% | 24.2% | 31.1% | 26.0% | 9.5% | 0.3% | 33.1% |
| 17 | 476416 | 58% | 37.9% | 34.4% | 33.5% | 1.2% | 26.3% | |||||||
| 18 | 489001 | 56% | 37.2% | 35.0% | 31.2% | 1.2% | 28.7% | |||||||
| 19 | 484655 | 53% | 36.6% | 35.4% | 29.2% | 1.1% | 30.9% | |||||||
| 20 | 495826 | 51% | 36.5% | 36.5% | 26.3% | 1.0% | 33.1% | |||||||
| 21 | 501457 | 49% | 35.7% | 37.3% | 23.9% | 1.0% | 35.5% | |||||||
| 22 | 510946 | 48% | 35.1% | 37.7% | 22.0% | 0.9% | 37.6% | |||||||
| 23 | 544895 | 49% | 34.7% | 38.5% | 19.5% | 0.8% | 39.8% | |||||||
| 24 | 563477 | 49% | 34.0% | 38.2% | 19.4% | 0.8% | 40.9% |
I also measured stream and it looks ~15% faster than my 7840 system.
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 100000000 (elements), Offset = 0 (elements)
Memory per array = 762.9 MiB (= 0.7 GiB).
Total memory required = 2288.8 MiB (= 2.2 GiB).
Each kernel will be executed 100 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 2
Number of Threads counted = 2
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 31409 microseconds.
(= 31409 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 86725.2 0.018665 0.018449 0.021070
Scale: 86626.7 0.018713 0.018470 0.020643
Add: 88192.8 0.027540 0.027213 0.031095
Triad: 87655.3 0.027729 0.027380 0.031028
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
Here is a phoronix article comparing Ryzen AI 9 HX 370 with a variety of laptop systems. The overall geomean is ~10% but there is a wider variety between tests. Can be interesting to puzzle out why some of the differences. It is also likely that the power points used for the laptop comparisons in the phoronix article are less since I see lower scores e.g. coremark or different gaps than what I see with the same benchmark. So will need to puzzle out some of the SOC/power choices.
Comments
New Ryzen AI 9 HX 370 machine — No Comments
HTML tags allowed in your comment: <a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>