
Benchmark workload of molecular dynamics shows approximately 50% of the slots are retiring.
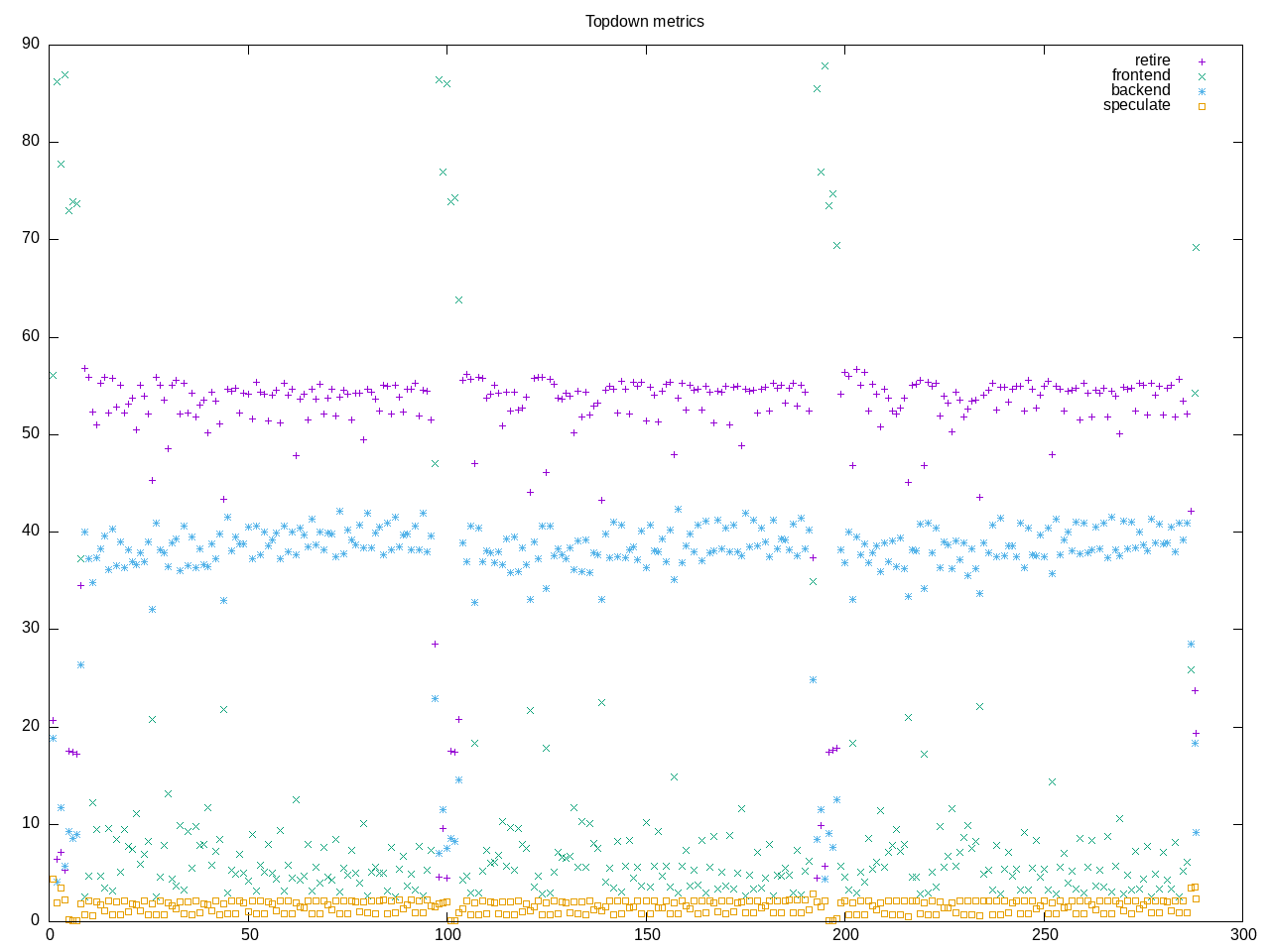
AMD metrics shows floating point intensive (2/3 of instructions are 128-bit floating point) without many branches and a small number of L2 access/miss. This results in slightly higher IPC and many instructions retired.
elapsed 329.070
on_cpu 0.952 # 15.24 / 16 cores
utime 4502.819
stime 511.863
nvcsw 163532 # 76.29%
nivcsw 50827 # 23.71%
inblock 252136 # 766.21/sec
onblock 97000 # 294.77/sec
cpu-clock 5014981624535 # 5014.982 seconds
task-clock 5015066062349 # 5015.066 seconds
page faults 1061669 # 211.696/sec
context switches 215829 # 43.036/sec
cpu migrations 361 # 0.072/sec
major page faults 357 # 0.071/sec
minor page faults 1061312 # 211.625/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 969457463749 # 27.144 branches per 1000 inst
branch misses 96604976909 # 9.96% branch miss
conditional 598626875725 # 16.761 conditional branches per 1000 inst
indirect 17759496963 # 0.497 indirect branches per 1000 inst
cpu-cycles 17843610263885 # 3.86 GHz
instructions 33685765494786 # 1.89 IPC
slots 35676676825020 #
retiring 11466401474400 # 32.1% (51.7%)
-- ucode 3261961494 # 0.0%
-- fastpath 11463139512906 # 32.1%
frontend 2110839683999 # 5.9% ( 9.5%)
-- latency 1773994098696 # 5.0%
-- bandwidth 336845585303 # 0.9%
backend 8262319364493 # 23.2% (37.3%)
-- cpu 4845859855349 # 13.6%
-- memory 3416459509144 # 9.6%
speculation 326075144679 # 0.9% ( 1.5%)
-- branch mispredict 322374538533 # 0.9%
-- pipeline restart 3700606146 # 0.0%
smt-contention 13511001433399 # 37.9% ( 0.0%)
cpu-cycles 17808305476130 # 3.85 GHz
instructions 33671204786751 # 1.89 IPC
instructions 11222058246597 # 29.363 l2 access per 1000 inst
l2 hit from l1 216808193838 # 3.37% l2 miss
l2 miss from l1 3534469784 #
l2 hit from l2 pf 105145731432 #
l3 hit from l2 pf 1270687312 #
l3 miss from l2 pf 6292933832 #
instructions 11221325446035 # 670.180 float per 1000 inst
float 512 67 # 0.000 AVX-512 per 1000 inst
float 256 976 # 0.000 AVX-256 per 1000 inst
float 128 7520307722746 # 670.180 AVX-128 per 1000 inst
float MMX 0 # 0.000 MMX per 1000 inst
float scalar 1008 # 0.000 scalar per 1000 instIntel metrics
elapsed 354.788
on_cpu 0.958 # 15.32 / 16 cores
utime 4737.499
stime 699.276
nvcsw 171768 # 79.34%
nivcsw 44733 # 20.66%
inblock 252000 # 710.28/sec
onblock 96864 # 273.02/sec
cpu-clock 5436887057539 # 5436.887 seconds
task-clock 5436946057116 # 5436.946 seconds
page faults 1078757 # 198.412/sec
context switches 218112 # 40.117/sec
cpu migrations 392 # 0.072/sec
major page faults 322 # 0.059/sec
minor page faults 1078434 # 198.353/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 1210384718995 # 44.673 branches per 1000 inst
branch misses 23841288511 # 1.97% branch miss
conditional 1210384729075 # 44.673 conditional branches per 1000 inst
indirect 335853367292 # 12.396 indirect branches per 1000 inst
slots 21038828152550 #
retiring 13684220792315 # 65.0% (65.0%)
-- ucode 2099158012732 # 10.0%
-- fastpath 11585062779583 # 55.1%
frontend 4772928176556 # 22.7% (22.7%)
-- latency 3153746942703 # 15.0%
-- bandwidth 1619181233853 # 7.7%
backend 2168742626552 # 10.3% (10.3%)
-- cpu 1685615965776 # 8.0%
-- memory 483126660776 # 2.3%
speculation 713253632021 # 3.4% ( 3.4%)
-- branch mispredict 653289250107 # 3.1%
-- pipeline restart 59964381914 # 0.3%
smt-contention 0 # 0.0% ( 0.0%)
cpu-cycles 7016247557601 # 1.38 GHz
instructions 13494156109832 # 1.92 IPC
l2 access 218890285131 # 16.221 l2 access per 1000 inst
l2 miss 32849187777 # 15.01% l2 missSummary information about the processes where most all time is spent in the namd process.
333 processes
51 namd2 71554.11 2492.20
38 vulkaninfo 0.57 1.15
6 glxinfo:gdrv0 0.09 0.09
4 vulkani:disk$0 0.06 0.13
2 glxinfo 0.06 0.03
2 glxinfo:cs0 0.06 0.03
6 php 0.05 0.07
2 glxinfo:disk$0 0.05 0.03
2 glxinfo:sh0 0.05 0.03
2 glxinfo:shlo0 0.05 0.03
6 clang 0.04 0.02
2 llvmpipe-0 0.03 0.07
2 llvmpipe-1 0.03 0.07
2 llvmpipe-10 0.03 0.07
2 llvmpipe-11 0.03 0.07
2 llvmpipe-12 0.03 0.07
2 llvmpipe-13 0.03 0.07
2 llvmpipe-14 0.03 0.07
2 llvmpipe-15 0.03 0.07
2 llvmpipe-2 0.03 0.07
2 llvmpipe-3 0.03 0.07
2 llvmpipe-4 0.03 0.07
2 llvmpipe-5 0.03 0.07
2 llvmpipe-6 0.03 0.07
2 llvmpipe-7 0.03 0.07
2 llvmpipe-8 0.03 0.07
2 llvmpipe-9 0.03 0.07
1 lspci 0.01 0.03
85 sh 0.00 0.00
12 gcc 0.00 0.00
9 stty 0.00 0.00
8 gsettings 0.00 0.00
8 stat 0.00 0.00
8 systemd-detect- 0.00 0.00
6 llvm-link 0.00 0.00
5 gmain 0.00 0.00
5 phoronix-test-s 0.00 0.00
3 dconf worker 0.00 0.00
3 namd 0.00 0.00
2 lscpu 0.00 0.00
2 uname 0.00 0.00
2 which 0.00 0.00
2 xset 0.00 0.00
1 cc 0.00 0.00
1 date 0.00 0.00
1 dirname 0.00 0.00
1 dmesg 0.00 0.00
1 dmidecode 0.00 0.00
1 grep 0.00 0.00
1 ifconfig 0.00 0.00
1 ip 0.00 0.00
1 lsmod 0.00 0.00
1 mktemp 0.00 0.00
1 ps 0.00 0.00
1 readlink 0.00 0.00
1 realpath 0.00 0.00
1 sed 0.00 0.00
1 sort 0.00 0.00
1 systemctl 0.00 0.00
1 template.sh 0.00 0.00
1 wc 0.00 0.00
1 xrandr 0.00 0.00
0 processes running
47 maximum processesWe run one process per core in the computation blocks
499497) namd start=4.84 finish=95.80
499498) namd2 start=4.84 finish=95.73
499499) namd2 start=4.85 finish=95.73
499500) namd2 start=4.85 finish=95.73
499501) namd2 start=4.85 finish=95.73
499502) namd2 start=4.85 finish=95.73
499503) namd2 start=4.85 finish=95.73
499504) namd2 start=4.85 finish=95.73
499505) namd2 start=4.85 finish=95.73
499506) namd2 start=4.85 finish=95.73
499507) namd2 start=4.85 finish=95.73
499508) namd2 start=4.85 finish=95.73
499509) namd2 start=4.85 finish=95.73
499510) namd2 start=4.85 finish=95.73
499511) namd2 start=4.85 finish=95.73
499512) namd2 start=4.85 finish=95.73
499513) namd2 start=4.85 finish=95.73
499514) namd2 start=4.86 finish=95.73