
Encode-mp3 is one of several quick-running encode benchmarks. These are quick-running high-IPC programs with just a two threads runnable at a time and an overall runtime of barely 10 seconds.

Topdown shows a quick running benchmark with high retirement rate.
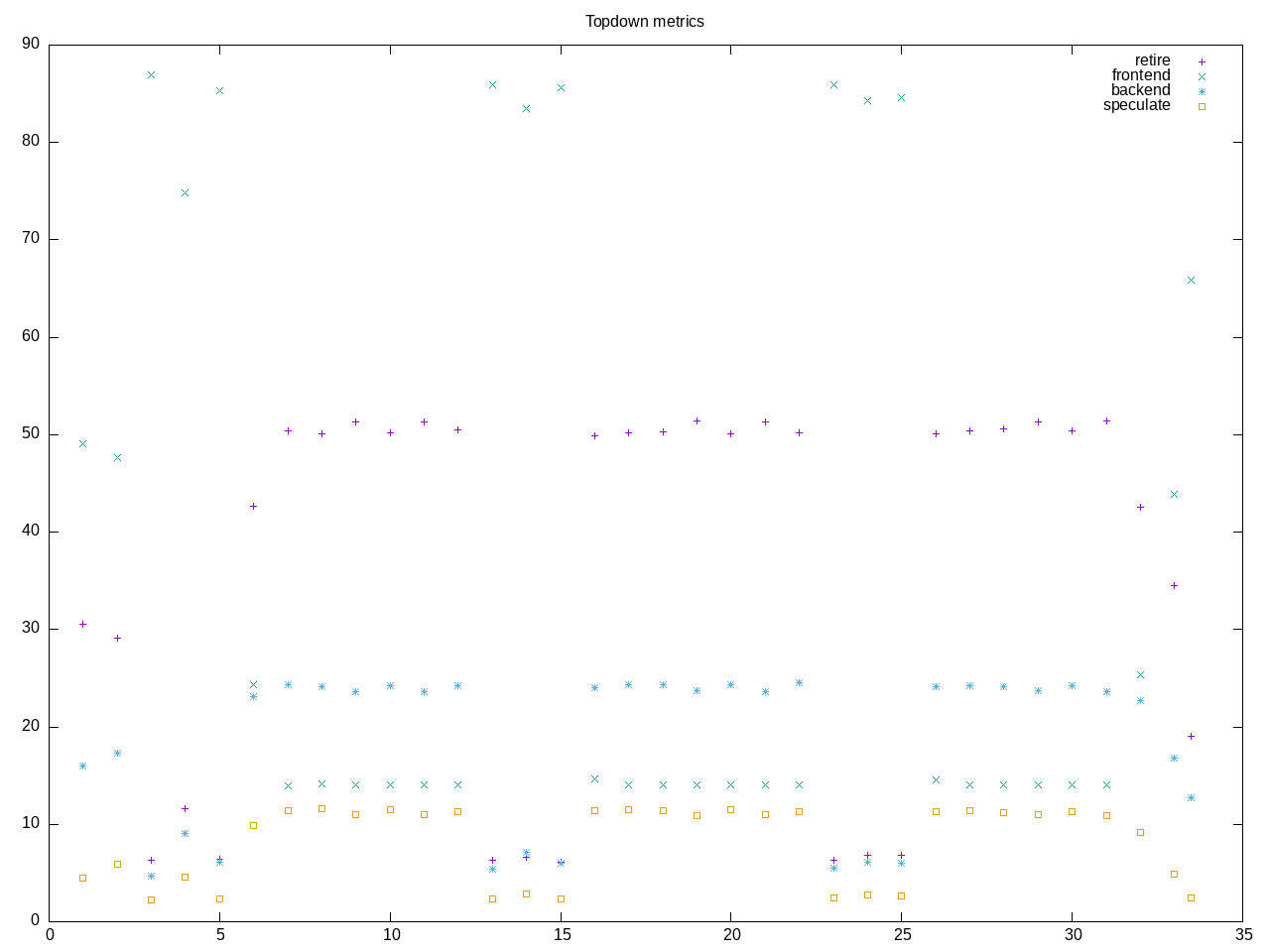
AMD metrics shows very low on cpu time and effectively a single-threaded benchmark. There is floating point code without as many branches.
elapsed 33.779
on_cpu 0.036 # 0.57 / 16 cores
utime 18.466
stime 0.823
nvcsw 2482 # 88.55%
nivcsw 321 # 11.45%
inblock 0 # 0.00/sec
onblock 12672 # 375.15/sec
cpu-clock 19301020946 # 19.301 seconds
task-clock 19303976750 # 19.304 seconds
page faults 152735 # 7912.100/sec
context switches 2799 # 144.996/sec
cpu migrations 256 # 13.262/sec
major page faults 2 # 0.104/sec
minor page faults 152733 # 7911.997/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 23522917061 # 94.639 branches per 1000 inst
branch misses 712436909 # 3.03% branch miss
conditional 20486508829 # 82.423 conditional branches per 1000 inst
indirect 187548801 # 0.755 indirect branches per 1000 inst
cpu-cycles 82476901747 # 0.16 GHz
instructions 246917957286 # 2.99 IPC
slots 167245156380 #
retiring 82289457515 # 49.2% (49.2%)
-- ucode 33116883 # 0.0%
-- fastpath 82256340632 # 49.2%
frontend 27123141375 # 16.2% (16.2%)
-- latency 16763183424 # 10.0%
-- bandwidth 10359957951 # 6.2%
backend 39585123505 # 23.7% (23.7%)
-- cpu 25160969294 # 15.0%
-- memory 14424154211 # 8.6%
speculation 18201692176 # 10.9% (10.9%)
-- branch mispredict 18155063485 # 10.9%
-- pipeline restart 46628691 # 0.0%
smt-contention 45471652 # 0.0% ( 0.0%)
cpu-cycles 82456469460 # 0.15 GHz
instructions 246330838196 # 2.99 IPC
instructions 82941767929 # 4.075 l2 access per 1000 inst
l2 hit from l1 273761018 # 6.95% l2 miss
l2 miss from l1 13761495 #
l2 hit from l2 pf 54478813 #
l3 hit from l2 pf 4628577 #
l3 miss from l2 pf 5090747 #
instructions 82660149687 # 267.806 float per 1000 inst
float 512 48 # 0.000 AVX-512 per 1000 inst
float 256 620 # 0.000 AVX-256 per 1000 inst
float 128 22136902767 # 267.806 AVX-128 per 1000 inst
float MMX 0 # 0.000 MMX per 1000 inst
float scalar 0 # 0.000 scalar per 1000 inst
Intel metrics
elapsed 37.303
on_cpu 0.039 # 0.62 / 16 cores
utime 22.777
stime 0.423
nvcsw 2383 # 91.87%
nivcsw 211 # 8.13%
inblock 1984 # 53.19/sec
onblock 1424 # 38.17/sec
cpu-clock 23197970753 # 23.198 seconds
task-clock 23200855061 # 23.201 seconds
page faults 137258 # 5916.075/sec
context switches 2610 # 112.496/sec
cpu migrations 263 # 11.336/sec
major page faults 12 # 0.517/sec
minor page faults 137246 # 5915.558/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 23206636870 # 93.834 branches per 1000 inst
branch misses 814296140 # 3.51% branch miss
conditional 23206648806 # 93.834 conditional branches per 1000 inst
indirect 194487089 # 0.786 indirect branches per 1000 inst
slots 520931539964 #
retiring 244222587693 # 46.9% (46.9%)
-- ucode 12467151855 # 2.4%
-- fastpath 231755435838 # 44.5%
frontend 78803572927 # 15.1% (15.1%)
-- latency 34466661193 # 6.6%
-- bandwidth 44336911734 # 8.5%
backend 92225261154 # 17.7% (17.7%)
-- cpu 70006065565 # 13.4%
-- memory 22219195589 # 4.3%
speculation 108336463165 # 20.8% (20.8%)
-- branch mispredict 108185792304 # 20.8%
-- pipeline restart 150670861 # 0.0%
smt-contention 0 # 0.0% ( 0.0%)
cpu-cycles 86786734054 # 0.15 GHz
instructions 247246722972 # 2.85 IPC
l2 access 614590123 # 2.490 l2 access per 1000 inst
l2 miss 85318593 # 13.88% l2 miss
Processes are straightforwar but just about as much time is spent in benchmark overhead as in the benchmark.
331 processes
6 lame 17.52 0.04
68 clinfo 15.54 6.98
38 vulkaninfo 0.57 1.52
6 glxinfo:gdrv0 0.15 0.06
2 glxinfo 0.07 0.02
2 glxinfo:cs0 0.07 0.02
2 glxinfo:disk$0 0.07 0.02
2 glxinfo:sh0 0.07 0.02
2 glxinfo:shlo0 0.07 0.02
4 vulkani:disk$0 0.06 0.16
6 php 0.05 0.09
5 clang 0.04 0.04
2 llvmpipe-0 0.03 0.08
2 llvmpipe-1 0.03 0.08
2 llvmpipe-10 0.03 0.08
2 llvmpipe-11 0.03 0.08
2 llvmpipe-12 0.03 0.08
2 llvmpipe-13 0.03 0.08
2 llvmpipe-14 0.03 0.08
2 llvmpipe-15 0.03 0.08
2 llvmpipe-2 0.03 0.08
2 llvmpipe-3 0.03 0.08
2 llvmpipe-4 0.03 0.08
2 llvmpipe-5 0.03 0.08
2 llvmpipe-6 0.03 0.08
2 llvmpipe-7 0.03 0.08
2 llvmpipe-8 0.03 0.08
2 llvmpipe-9 0.03 0.08
3 rocminfo 0.03 0.00
1 lspci 0.00 0.02
74 sh 0.00 0.00
12 gsettings 0.00 0.00
10 gcc 0.00 0.00
7 stat 0.00 0.00
7 systemd-detect- 0.00 0.00
5 llvm-link 0.00 0.00
5 phoronix-test-s 0.00 0.00
3 gmain 0.00 0.00
2 lscpu 0.00 0.00
2 stty 0.00 0.00
2 uname 0.00 0.00
2 which 0.00 0.00
2 xset 0.00 0.00
1 cc 0.00 0.00
1 date 0.00 0.00
1 dconf worker 0.00 0.00
1 dirname 0.00 0.00
1 dmesg 0.00 0.00
1 dmidecode 0.00 0.00
1 grep 0.00 0.00
1 ifconfig 0.00 0.00
1 ip 0.00 0.00
1 lsmod 0.00 0.00
1 mktemp 0.00 0.00
1 qdbus 0.00 0.00
1 readlink 0.00 0.00
1 realpath 0.00 0.00
1 sed 0.00 0.00
1 sort 0.00 0.00
1 template.sh 0.00 0.00
1 wc 0.00 0.00
1 xrandr 0.00 0.00
0 processes running
47 maximum processes
The entire computation is only six processes of “lame”, the rest is all overhead.
42818) lame cpu=1 start=5.49 finish=11.33
42819) lame cpu=2 start=5.49 finish=11.33
42820) lame cpu=15 start=15.33 finish=21.21
42821) lame cpu=1 start=15.33 finish=21.21
42822) lame cpu=15 start=25.22 finish=31.09
42823) lame cpu=0 start=25.22 finish=31.09