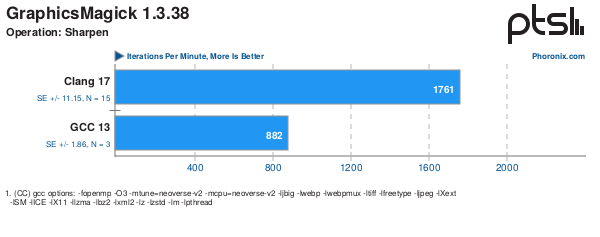
The following Phoronix Article – https://www.phoronix.com/review/nvidia-gh200-compilers compares GCC 13.2 with Clang 17.0.2 on an ARM platform. On the discussions attached the improvement for graphics-magick sharpen benchmark particularly stand out. So I thought I would see if I could see a similar improvement and using performance tools could spot likely areas contributing to the difference.
My system has Ubuntu 22.04 system compiler or gcc 11.4 and also aocc 4.1 based on clang 16.0.3 so not exactly the same but close enough. I forced a rebuild by reinstalling the test and setting environment variables, e.g.
export CC=/opt/AMD/aocc-compiler-4.1.0/bin/clang
export CXX=/opt/AMD/aocc-compiler-4.1.0/bin/clang++
export CFLAGS="-O3 -march=native"
export CXXFLAGS="-O3 -march=native"With these differences, I see the following with gcc 11.4
Operation: Sharpen:
107
108
108
Average: 108 Iterations Per Minute
Deviation: 0.54%and the following differences with clang 16.0
Operation: Sharpen:
177
178
178
Average: 178 Iterations Per Minute
Deviation: 0.32%
So overall a 1.65x speedup. Noy quite the 2x speedup seen on the AArch64 system but close enough given different compilers.
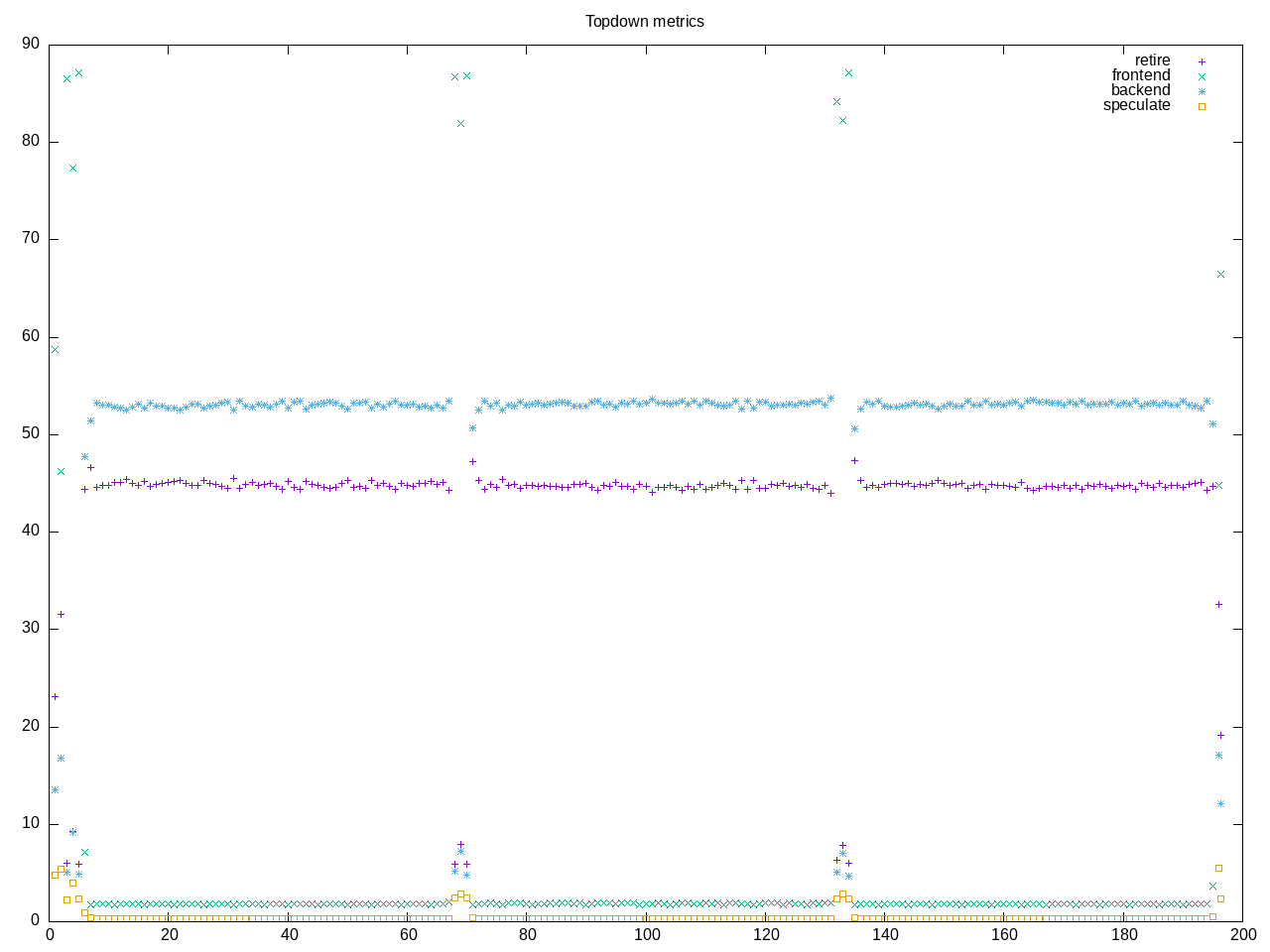
Here is what my topdown profile shows for gcc
Here is the comparison point with clang
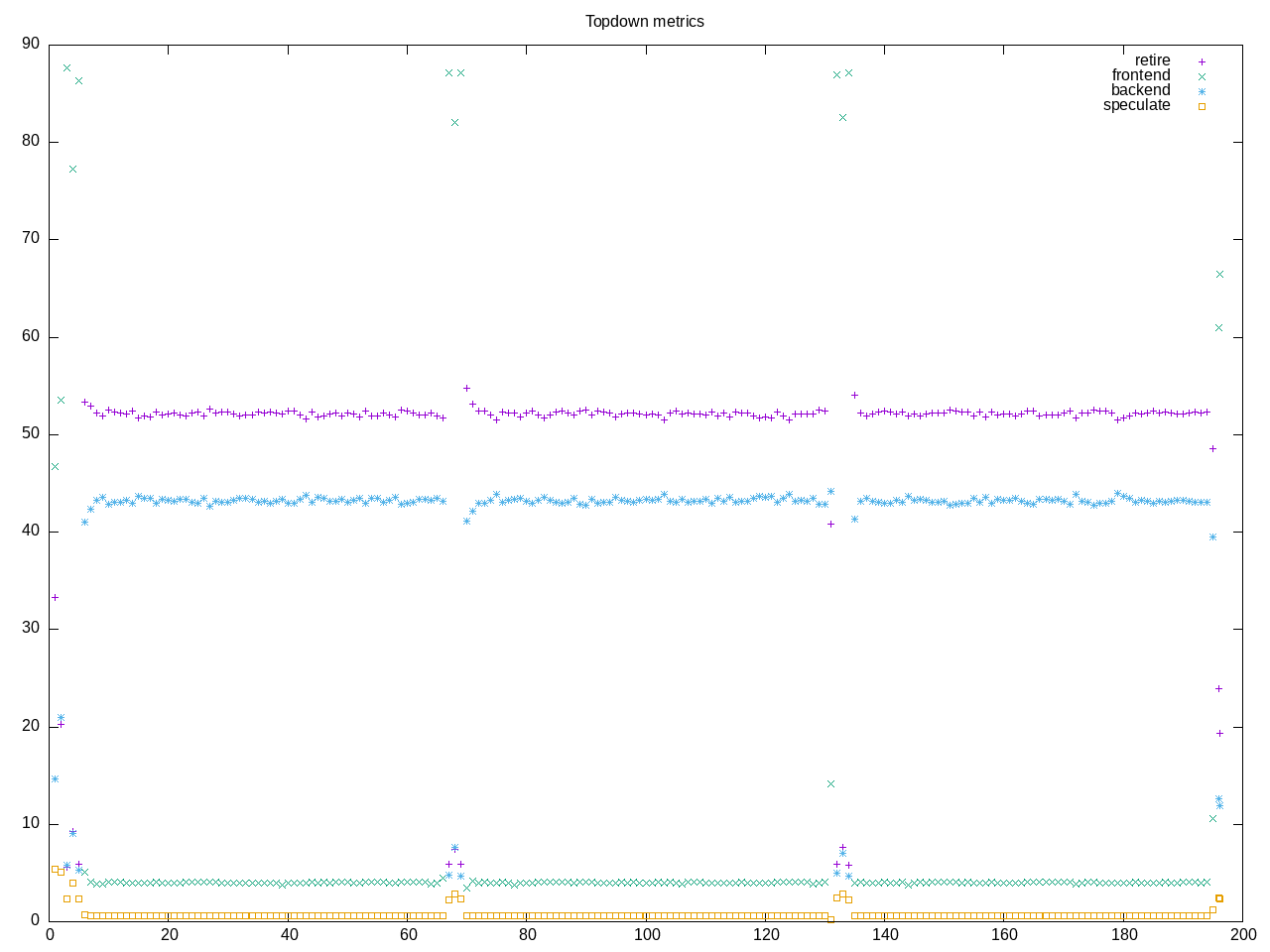
Interestingly the total runtime is close to the same (time-bound test?) but we definitely have dropped backend stalls in favor of retiring a higher percentage of instructions.
Here is what the metrics show for gcc
elapsed 196.669
on_cpu 0.912 # 14.59 / 16 cores
utime 2847.753
stime 22.595
nvcsw 7799 # 21.59%
nivcsw 28324 # 78.41%
inblock 72 # 0.37/sec
onblock 12832 # 65.25/sec
cpu-clock 2870386800612 # 2870.387 seconds
task-clock 2870418438024 # 2870.418 seconds
page faults 8219671 # 2863.579/sec
context switches 36937 # 12.868/sec
cpu migrations 252 # 0.088/sec
major page faults 3 # 0.001/sec
minor page faults 8219668 # 2863.578/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 1140203600927 # 59.971 branches per 1000 inst
branch misses 9706629710 # 0.85% branch miss
conditional 1123801038031 # 59.108 conditional branches per 1000 inst
indirect 79758239 # 0.004 indirect branches per 1000 inst
cpu-cycles 12006859596451 # 3.83 GHz
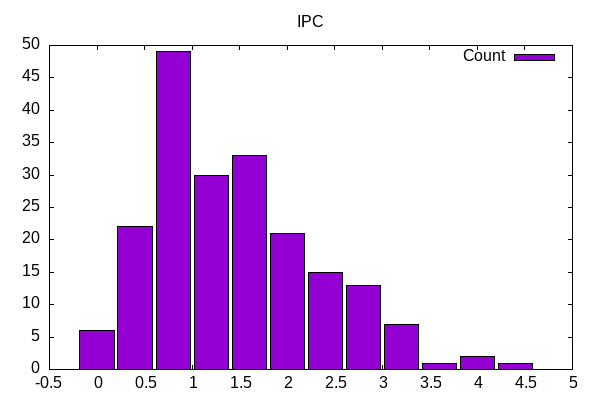
instructions 18841741204039 # 1.57 IPC
slots 24015874376394 #
retiring 6873291214752 # 28.6% (44.9%)
-- ucode 776914684 # 0.0%
-- fastpath 6872514300068 # 28.6%
frontend 280560426894 # 1.2% ( 1.8%) low
-- latency 204333739230 # 0.9%
-- bandwidth 76226687664 # 0.3%
backend 8106573021445 # 33.8% (52.9%)
-- cpu 7904629941195 # 32.9%
-- memory 201943080250 # 0.8%
speculation 52507444606 # 0.2% ( 0.3%) low
-- branch mispredict 52421287288 # 0.2%
-- pipeline restart 86157318 # 0.0%
smt-contention 8702915928072 # 36.2% ( 0.0%)
cpu-cycles 12008757786517 # 3.84 GHz
instructions 18832540244485 # 1.57 IPC
instructions 6279648919771 # 2.124 l2 access per 1000 inst
l2 hit from l1 7173349879 # 20.29% l2 miss
l2 miss from l1 704685663 #
l2 hit from l2 pf 4162164156 #
l3 hit from l2 pf 1757001598 #
l3 miss from l2 pf 244954442 #
instructions 6277843164084 # 351.548 float per 1000 inst
float 512 57 # 0.000 AVX-512 per 1000 inst
float 256 584 # 0.000 AVX-256 per 1000 inst
float 128 2206965520855 # 351.548 AVX-128 per 1000 inst
float MMX 0 # 0.000 MMX per 1000 inst
float scalar 0 # 0.000 scalar per 1000 inst
instructions 18950819136221 #
opcache 2107351794817 # 111.201 opcache per 1000 inst
opcache miss 9523189344 # 0.5% opcache miss rate
l1 dTLB miss 902958198 # 0.048 L1 dTLB per 1000 inst
l2 dTLB miss 68055690 # 0.004 L2 dTLB per 1000 inst
instructions 18892305597227 #
icache 18578037535 # 0.983 icache per 1000 inst
icache miss 1477678165 # 8.0% icache miss rate
l1 iTLB miss 8626682 # 0.000 L1 iTLB per 1000 inst
l2 iTLB miss 0 # 0.000 L2 iTLB per 1000 inst
tlb flush 34816 # 0.000 TLB flush per 1000 inst
Here is what they show for clang
elapsed 198.605
on_cpu 0.910 # 14.55 / 16 cores
utime 2846.489
stime 43.933
nvcsw 10817 # 26.18%
nivcsw 30507 # 73.82%
inblock 8 # 0.04/sec
onblock 12904 # 64.97/sec
cpu-clock 2890592540363 # 2890.593 seconds
task-clock 2890613273288 # 2890.613 seconds
page faults 13446401 # 4651.747/sec
context switches 42134 # 14.576/sec
cpu migrations 320 # 0.111/sec
major page faults 51 # 0.018/sec
minor page faults 13446350 # 4651.729/sec
alignment faults 0 # 0.000/sec
emulation faults 0 # 0.000/sec
branches 1895985554702 # 85.338 branches per 1000 inst
branch misses 16208435546 # 0.85% branch miss
conditional 1856679790302 # 83.569 conditional branches per 1000 inst
indirect 162624101 # 0.007 indirect branches per 1000 inst
cpu-cycles 11802414391046 # 3.76 GHz
instructions 22167963494891 # 1.88 IPC
slots 23606223963606 #
retiring 7476214292393 # 31.7% (52.1%)
-- ucode 3459130581 # 0.0%
-- fastpath 7472755161812 # 31.7%
frontend 577593637926 # 2.4% ( 4.0%) low
-- latency 362394713874 # 1.5%
-- bandwidth 215198924052 # 0.9%
backend 6205319253065 # 26.3% (43.3%)
-- cpu 5685432163067 # 24.1%
-- memory 519887089998 # 2.2%
speculation 83292194787 # 0.4% ( 0.6%) low
-- branch mispredict 83160520795 # 0.4%
-- pipeline restart 131673992 # 0.0%
smt-contention 9263789209330 # 39.2% ( 0.0%)
cpu-cycles 11818914678350 # 3.74 GHz
instructions 22211450935976 # 1.88 IPC
instructions 7404943446705 # 2.939 l2 access per 1000 inst
l2 hit from l1 11586386135 # 19.79% l2 miss
l2 miss from l1 1111590991 #
l2 hit from l2 pf 6979543347 #
l3 hit from l2 pf 2793906722 #
l3 miss from l2 pf 399941912 #
instructions 7400104673984 # 491.708 float per 1000 inst
float 512 72 # 0.000 AVX-512 per 1000 inst
float 256 668 # 0.000 AVX-256 per 1000 inst
float 128 3638689694804 # 491.708 AVX-128 per 1000 inst
float MMX 0 # 0.000 MMX per 1000 inst
float scalar 0 # 0.000 scalar per 1000 inst
instructions 22251978896991 #
opcache 3428837218389 # 154.091 opcache per 1000 inst
opcache miss 16257852042 # 0.5% opcache miss rate
l1 dTLB miss 1527716103 # 0.069 L1 dTLB per 1000 inst
l2 dTLB miss 108536720 # 0.005 L2 dTLB per 1000 inst
instructions 22248633347533 #
icache 35471913129 # 1.594 icache per 1000 inst
icache miss 1971706421 # 5.6% icache miss rate
l1 iTLB miss 9490954 # 0.000 L1 iTLB per 1000 inst
l2 iTLB miss 0 # 0.000 L2 iTLB per 1000 inst
tlb flush 71325 # 0.000 TLB flush per 1000 inst
Looking with a rough comparison I notice:
- User time is almost identical so likely some time-bounded loop
- There are more instructions overall, and particularly AVX-128 has gone from 351 per thousand to 491 per thousand. The number of branches has also gone up
- IPC has gone from 1.57 to 1.88.
Based on this my likely guess is some greater vectorization to tighten the core loop. This indirectly results in more branches (smaller loop). CPU stalls still contribute most to backend stalls but have gone down while number of vector instructions have gone up.
There may be other more direct ways to compare compiler options and results, but this is at least an indirect way to view the effects looking at the overall performance characterization.