Performance analysis, tools and experimentsPosted on by mev
As a follow up to previous posting looking at Ryzen AI HX 370, I have also done some SPEC CPU2017 experiments. My general idea is to compare the two processors with a few caveats:
I have used a configuration file roughly based on AMD Server configuration files and using the AMD AOCC compiler. However, because I am not trying to publish the absolute best results for hardware (and haven’t tuned to do so) – I will report relative comparison results rather than absolute numbers.
I expect AMD to release a new version of AMD AOCC for the Zen5 core. I didn’t have it when I did these comparisons and like using the same flags on both systems so these comparisons used the same flags for both Zen4 and Zen5 systems.
SPEC CPU2017 guidelines give a requirement of 2 GB of memory per core. My Ryzen 370 system has 24 cores and only 32 GB of memory. So I expect some benchmarks might run out of memory. For this reason and trying to get an overall comparison I’ve thus done two runs:
A 16-copy run on both systems. This uses all (hyperthreaded) cores on the Ryzen 7840 HS and a mix of hyperthreading of Zen5 cores + non-hyperthreading of Zen5C cores.
A 24-copy run on the Ryzen 370 system.
Relative results are shown in the tables below. This gives me some opportunities to drill a little deeper on why some benchmarks have larger gains than others.
Overall the differences between 16 threads and 24 threads are interesting. Using 24 threads seems to mostly help the intrate benchmarks with the geomean going from +12% to +21% and every benchmark improving vs 7840. Overall, using 24 threads seems to be more mixed with fprate. On average slightly slower than 16-threads. In both cases, the individual benchmarks also differ.
16-thread
24-thread
500.perlbench_r
1.12
1.24
502.gcc_r
1.17
1.15
505.mcf_r
1.09
1.21
520.omnetpp_r
1.07
1.16
523.xalancbmk_r
1.35
1.23
525.x264_r
1.19
1.31
531.deepsjeng_r
1.11
1.18
541.leela_r
0.94
1.07
548.exchange_r
1.24
1.38
557.xz_r
0.96
1.16
geomean
1.12
1.21
My intrate comparisons range from -6% to +35% with a geometric mean of +12%
16-thread
24-thread
503.bwaves_r
1.11
1.09
507.cactuBSSN_r
1.30
1.25
508.namd_r
1.22
1.34
510.parest_r
1.53
1.10
511.povray_r
1.19
1.30
519.lbm_r
1.63
1.59
521.wrf_r
1.32
1.17
526.blender_r
1.24
1.27
527.cam4_r
1.61
1.45
538.imagick_r
1.19
1.32
544.nab_r
1.19
1.31
549.fotonik_r
1.11
1.09
554.roms_r
1.43
1.15
geomean
1.30
1.26
My fprate comparisons range from +11% to +63% with a geometric mean of +30%
Performance analysis, tools and experimentsPosted on by mev
As a follow up comparison of Ryzen AI HX 370 processor compared to Ryzen 7840 HS, this posting looks at some Phoronix benchmarks.
I’ve run more than 200 Phoronix benchmarks in analysis using performance counters. I use these clusters to guide the benchmarks chosen trying to pick one from each cluster. In some cases where the benchmark didn’t easily run on Ubuntu 24.04, I skipped to another benchmark rather than debug the original issue. A cluster list from September 2024 below:
Following is a summary of the benchmarks followed by some observations
cluster
benchmark
metric ratio
7840 metric
hx 370 metric
7840 on cpu
hx 370 on cpu
7840 retire
hx 370 retire
7840 frontend
hx 370 frontend
7840 backend
hx 370 backend
7840 speculation
hx 370 speculation
0
ospray
1.58
3.87314 / second
6.07719 /sec
14.46
21.28
29.3%
30.7%
27.3%
11.8%
41.1%
54.2%
2.3%
2.4%
1
compress-xz
0.96
28.665 seconds
29.736 seconds
11.04
12.45
8.2%
7.3%
10.2%
17.3%
76.5%
68.2%
5.1%
7.1%
2
quicksilver
1.41
12610000 fom
1776333 fom
15.38
19.9%
49.8%
15.9%
6.9%
15.9%
38.9%
59.5%
4.4%
2.7%
3
x265
1.65
13.79 frames/second
22.81 frames/sec
7.72
11.62
35.0%
26.9%
14.3%
22.5%
48.0%
47.4%
2.7%
3.0%
4
coremark
1.37
411227 iterations/sec
561065 iterations/sec
11.98
14.43
45.7%
37.0%
39.7%
42.0%
14.2%
20.2%
0.3%
0.8%
5
build-eigen
0.77
63.356 seconds
82.516 seconds
0.93
0.94
25.2%
20.4%
50.5%
52.8%
18.6%
21.9%
5.6%
4.8%
6
build-gcc
1.06
1038.166 seconds
976.243 seconds
9.98
10.91
24.1%
18.3%
51.5%
60.0%
19.7%
18.2%
4.7%
3.1%
7
phpbench
0.77
1159425 score
900908 score
0.80
0.83
61.2%
48.6%
23.0%
30.1%
15.0%
20.1%
0.8%
1.1%
8
lzbench
0.58
192 MB/s
111 MB/s
0.80
0.82
34.1%
22.7%
26.3%
36.5%
21.5%
21.2%
18.1%
19.4%
9
compress-zstd
1.01
1534.8 MB/s
1556.6 MB/s
4.23
3.45
21.4%
18.3%
9.5%
17.8%
62.8%
55.7%
6.3%
0.2%
10
simdjson
0.79
5.58 GB/s
4.41 GB/s
0.93
0.94
50.4%
42.7%
13.1%
27.0%
33.2%
28.0%
3.3%
1.5%
11
perl-benchmark
0.78
0.068363375 seconds
0.08713901 seconds
0.93
0.92
43.0%
35.5%
41.8%
41.7%
11.1%
18.0%
4.2%
4.6%
12
ffmpeg
0.99
252.66 fps
251.11 fps
3.67
2.61
32.3%
29.1%
18.4%
30.3%
29.0%
33.8%
5.6%
6.7%
13
compress-gzip
0.69
28.116 seconds
40.597 seconds
0.96
0.95
19.9%
15.1%
26.4%
29.1%
42.0%
43.0%
11.7%
12.7%
14
povray
1.34
38.681 seconds
28.778 seconds
13.32
18.83
31.8%
40.1%
3.5%
16.3%
25.5%
41.5%
1.3%
2.0%
15
whisperfile
1.11
54.13398 seconds
48.57337 seconds
7.44
10.81
20.0%
15.2%
2.2%
15.5%
77.3%
68.9%
0.3%
0.3%
16
easywave
1.26
8.809 seconds
7.005 seconds
14.60
20.53
4.5%
4.8%
3.1%
15.1%
83.6%
74.6%
0.1%
0.1%
17
darktable
1.34
5.711 seconds
4.267 seconds
3.42
5.50
27.9%
19.1%
7.2%
15.2%
63.5%
60.9%
1.3%
1.0%
18
compress-7zip
1.01
76676 MIPS
77409 MIPS
12.03
17.27
21.5%
13.0%
38.6%
53.5%
29.1%
19.7%
10.8%
13.8%
19
himeno
1.07
4447 MFLOPS
4769 MFLOPS
0.91
0.91
26.4%
33.3%
2.5%
2.7%
71.0%
63.7%
0.2%
0.3%
20
minibude
1.36
537.395 GFinst/s
733.427 GFInst/s
15.36
20.51
19.8%
18.7%
0.3%
1.6%
79.8%
79.0%
0.1%
0.4%
21
ebizzy
0.18
774839 records/s
140179 records/s
12.87
19.82
7.3%
0.6%
35.3%
63.1%
57.3%
36.3%
0.0%
0.0%
22
pjsip
0.79
4613 response/sec
3665 response/sec
2.40
2.23
12.2%
11.3%
38.4%
33.9%
48.4%
51.3%
1.1%
1.1%
23
openssl
1.63
15219867520 bytes/s
17696663040 bytes/s
15.51
23.25
46.5%
33.4%
4.9%
13.3%
48.7%
53.2%
0.0%
0.0%
24
build-php
1.16
67.052 seconds
65.354 seconds
8.30
10.20
20.8%
15.1%
50.4%
57.0%
24.8%
24.1%
3.9%
3.4%
25
pybench
0.84
554 ms
663 ms
0.75
0.79
70.1%
63.9%
15.9%
17.0%
11.4%
17.0%
2.6%
2.1%
26
dbench
3.74
687.037 MB/s
2573 MB/s
1.05
2.06
19.4%
22.2%
70.0%
38.3%
9.9%
37.5%
0.7%
0.9%
27
indigobench
1.40
2.090 samples/sec
2.917 samples/sec
14.14
21.25
25.8%
19.9%
14.8%
29.3%
54.0%
44.9%
5.4%
5.4%
28
lczero
1.41
108 nodes/sec
152 nodes/sec
13.23
18.34
16.8%
14.3%
4.4%
3.8%
78.7%
81.6%
0.1%
0.1%
29
rawtherapee
1.05
54.194 seconds
51.600 seconds
7.71
10.19
29.0%
18.5%
12.6%
27.1%
57.0%
44.8%
1.5%
1.3%
The first observation is most all single-threaded benchmarks run faster on the 7840 than on the Strix 370. In contrast the largest differences are among those with largest number of “on_cpu” threads.
There are two outliers that deserve a second look:
ebizzy is over 5x faster on 7840 than hx 370. This benchmark runs quickly so need to make sure it is running correctly in both instances. I don’t see these ratios in the two SPEC CPU2017 benchmarks also part of this group.
dbench runs over 3x faster on hx370 than 7840. The on_cpu is almost twice. Again useful to understand if there is another influence affecting this benchmark. Perhaps this one testing something else.
Agner Fog architecture document and likwid-topology
lmbench
L1 – 0.8 ns
L2 – 3 ns
L3 – 8 ns
L1 – 0.8 ns
L2 – 3ns
L3 – 8 ns
Measured in Nanoseconds
Graphics
Radeon 780M
12 cores
2700 MHz
Radeon 890M
16 cores
2900 MHz
Phoronix stream
Average: 40604 MB/s
Average 44500 MB/s
Phoronix coremark
Average 464076 Iterations/second
Average 563477 Iterations/second
+21%
Following are the results from likwid-topology. This is a hybrid core with four Zen5 cores and eight Zen5c cores. I believe the first four cores are Zen5 and the remaining eight are Zen5c.
The L3 cache amount may be incorrect as specifications suggest 24 MB of cache. Using lmbench suggests the L3 cache attached to first four cores is 16MB and the next groups have 8MB likely together even though topology above makes them separate.
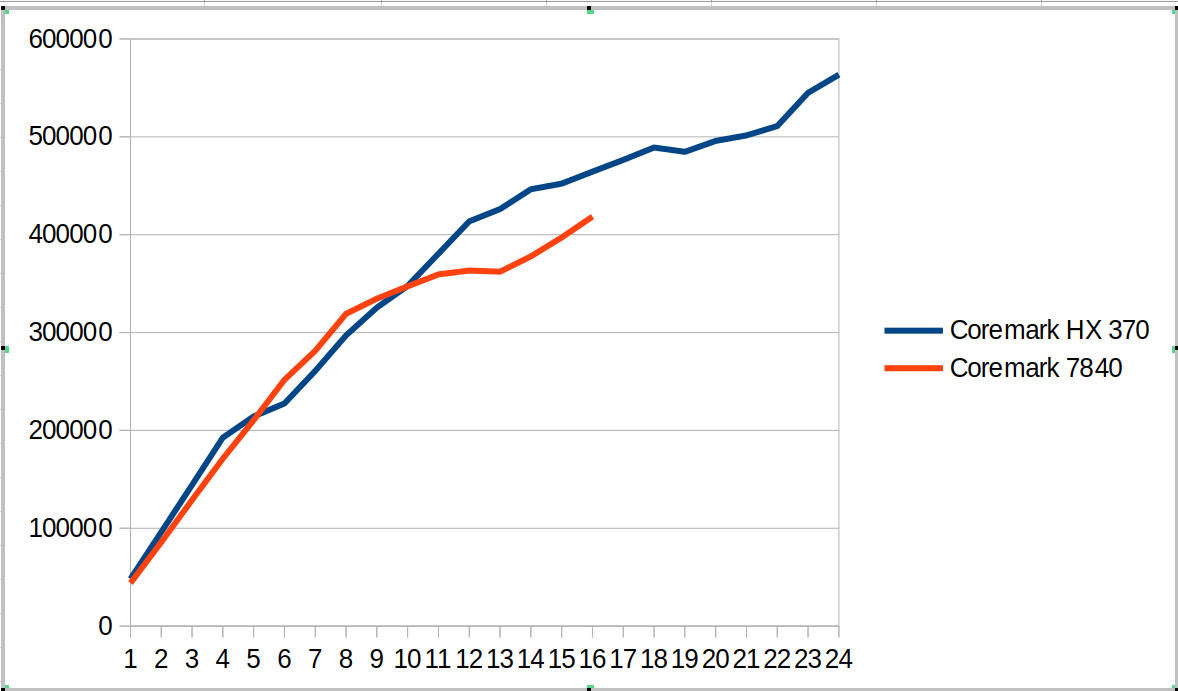
This hybrid SOC shows up in the following coremark scaling comparison as shown in the graph below. There are several different regions
From 1 to 4 cores we compare Zen4 cores against Zen5 cores. The coremark value for 4 cores is ~12% ahead.
From 5 to 8 cores, we now have Zen5 + Zen5C cores against Zen4 cores. The coremark value for 8 cores is ~7% behind
From 9 to 12 cores, we use all the cores on HX 370 and start using SMT for the 7840. The coremark value for 12 cores is 6% ahead
From 13 to 16 cores we go to using SMT for all the Zen5 cores and not-SMT for Zen5C cores. The 7840 moves to fully SMT. The coremark value for 16 cores is 11% ahead
From 17 to 24 cores, we go to adding SMT for Zen5C cores. The overall coremark using all cores (24 vs 16) is 21% ahead.
This suggests for coremark and other workloads there will be different regions where combinations of SMT and Zen5 vs Zen5C cores will create interesting comparisons between the systems.
The tabular version of coremark including performance counters is shown below.
Cores
Coremark HX 370
Coremark 7840
Scaling HX 370
Scaling 7840
Retiring HX 370
Frontend HX 370
Backend HX 370
Speculation HX 370
SMT-contention HX 370
Retiring 7840
Frontend 7840
Backend 7840
Speculation 7840
SMT-contention 7840
1
48245
43881
100%
100%
44.2%
25.2%
62.0%
2.0%
0.0%
43.9%
12.4%
43.0%
0.7%
0.0%
2
96106
85758
100%
98%
44.0%
25.5%
61.8%
2.0%
0.0%
43.9%
12.4%
43.1%
0.7%
0.0%
3
144147
128841
100%
98%
44.0%
25.5%
61.8%
2.0%
0.0%
43.6%
13.0%
42.7%
0.7%
0.0%
4
192537
171061
100%
97%
44.1%
25.4%
61.9%
2.0%
0.0%
43.9%
12.3%
43.1%
0.7%
0.0%
5
214223
210368
89%
96%
44.0%
25.5%
61.8%
2.0%
0.0%
43.9%
12.3%
43.1%
0.7%
0.0%
6
227532
251705
79%
96%
44.0%
25.4%
61.9%
2.0%
0.0%
43.2%
12.9%
43.2%
0.7%
0.0%
7
260811
281369
77%
92%
44.0%
25.7%
61.7%
2.0%
0.0%
43.3%
12.2%
43.7%
0.7%
0.0%
8
297002
319098
77%
91%
44.1%
25.3%
61.9%
2.0%
0.0%
42.7%
12.8%
43.8%
0.7%
0.0%
9
325417
334602
75%
85%
44.1%
25.3%
62.0%
2.0%
0.0%
40.2%
15.9%
36.3%
0.6%
7.1%
10
347636
347246
72%
79%
44.0%
25.3%
61.9%
2.0%
0.0%
38.4%
17.8%
30.2%
0.5%
13.1%
11
380587
359402
72%
74%
44.0%
25.5%
61.8%
2.0%
0.0%
36.9%
19.6%
25.3%
0.5%
17.8%
12
413575
363288
71%
69%
44.0%
25.4%
61.9%
2.0%
0.0%
35.5%
21.1%
21.6%
0.4%
21.3%
13
426123
362144
68%
63%
42.1%
28.2%
52.9%
1.8%
8.3%
34.4%
22.4%
18.5%
0.4%
24.3%
14
446379
377767
66%
61%
40.5%
30.6%
45.6%
1.6%
15.1%
33.1%
24.4%
15.2%
0.4%
26.9%
15
452134
397145
62%
60%
39.5%
32.2%
40.6%
1.4%
19.7%
32.2%
25.3%
12.0%
0.3%
30.2%
16
464431
418462
60%
60%
38.3%
33.7%
35.8%
1.3%
24.2%
31.1%
26.0%
9.5%
0.3%
33.1%
17
476416
58%
37.9%
34.4%
33.5%
1.2%
26.3%
18
489001
56%
37.2%
35.0%
31.2%
1.2%
28.7%
19
484655
53%
36.6%
35.4%
29.2%
1.1%
30.9%
20
495826
51%
36.5%
36.5%
26.3%
1.0%
33.1%
21
501457
49%
35.7%
37.3%
23.9%
1.0%
35.5%
22
510946
48%
35.1%
37.7%
22.0%
0.9%
37.6%
23
544895
49%
34.7%
38.5%
19.5%
0.8%
39.8%
24
563477
49%
34.0%
38.2%
19.4%
0.8%
40.9%
I also measured stream and it looks ~15% faster than my 7840 system.
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 100000000 (elements), Offset = 0 (elements)
Memory per array = 762.9 MiB (= 0.7 GiB).
Total memory required = 2288.8 MiB (= 2.2 GiB).
Each kernel will be executed 100 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 2
Number of Threads counted = 2
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 31409 microseconds.
(= 31409 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 86725.2 0.018665 0.018449 0.021070
Scale: 86626.7 0.018713 0.018470 0.020643
Add: 88192.8 0.027540 0.027213 0.031095
Triad: 87655.3 0.027729 0.027380 0.031028
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
Here is a phoronix article comparing Ryzen AI 9 HX 370 with a variety of laptop systems. The overall geomean is ~10% but there is a wider variety between tests. Can be interesting to puzzle out why some of the differences. It is also likely that the power points used for the laptop comparisons in the phoronix article are less since I see lower scores e.g. coremark or different gaps than what I see with the same benchmark. So will need to puzzle out some of the SOC/power choices.
Performance analysis, tools and experimentsPosted on by mev
The following chart shows the Phoronix test suite coremark value when running from 1 to 16 cores. Graphically it looks as follows The question is what causes the inflection points on the graph? The scaling from 1-8 cores decreases only …Continue reading →
Performance analysis, tools and experimentsPosted on by mev
I have set up a new AMD performance machine for experiments. The processors is a Ryzen 7840 (Phoenix) in a Beelink SER7 mini-PC. Following are some of the major parameters. This comparison is with Intel i5-13500H which will be my …Continue reading →