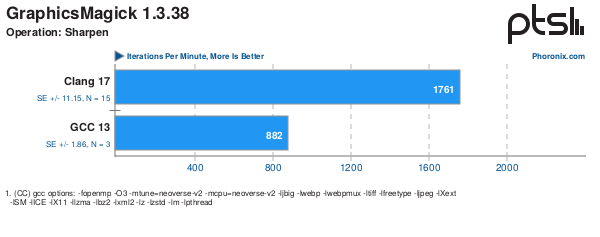
I have reached the point of diminishing returns for Phoronix tests. Reached 240 workloads analyzed and another ~30+ workloads that are skipped, mostly as GPU centric tests. These 270+ tests fully cover the 56 Phoronix benchmark articles so far this year. It has also become increasingly rare for a new article to reference an uncharacterized Phoronix test. When this happens, I will add to my analysis but I don’t see as much point in going through other, often obsolete workload examples. So I expect this to slowly creep up but not that quickly.
SPEC CPU is an interesting workload both as a workload and as a study of performance counters. There were three general issues that kept me from jumping full-bore into adding SPEC CPU until now:
- The suite is expensive, ~$1000
- My point is to characterize it as a workload, not to create hardware measurements. There are both detailed reporting rules and an emphasis on publicizing SPEC numbers to measure/compare hardware. While I would like the code to be somewhat optimized, I am also not trying for the absolute highest scores. So I will refrain from creating specific numbers with my “estimates” and use compiler options that I generally find without searching for optimal
- SPEC CPU is a good measure of processor, memory and compiler. So for these measurements, I created config files with AMD AOCC compiler suite.
SPEC CPU has both rate benchmarks and speed benchmarks. The rate benchmarks maximize throughput, running multiple copies typically one per logical core. The speed benchmarks minimize latency, sometimes one copy but now also using OpenMP as it makes sense. I have concentrated first on the rate benchmarks. Looking at their profiles, I see some commonality between them and occasional variation with many Phoronix benchmarks.
| benchmark | status | elapsed | on_cpu | inblock | onblock | page-fault | context-switch | IPC | GHz | retire-rate | frontend-stall | backend-stall | spec-stall | retire-ucode | retire-fastpath | float-density | frontend-latency | frontend-bandwidth | opcache-miss | icache-miss | backend-cpu | backend-memory | amd-l2-miss | amd-l2-density | spec-branch | spec-pipeline | branch-miss | branch-density | branch-cond | branch-ind | smt-contention |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500.perlbench_r | CPU | 1272.531 | 15.75 | 0.02 | 542.18 | 389.437 | 10.721 | 1.58 | 4.10 | 33.3 | 19.7 | 44.7 | 2.3 | 0.1 | 25.2 | 16.803 | 8.8 | 6.2 | 5.6 | 42.5 | 3.1 | 30.8 | 11.62 | 15.736 | 1.7 | 0.1 | 0.63 | 184.569 | 132.594 | 12.996 | 23.9 |
| 502.gcc_r | CPU | 1280.597 | 15.70 | 0.00 | 4845.61 | 26600.971 | 10.948 | 0.60 | 4.39 | 12.7 | 25.6 | 59.8 | 1.9 | 0.0 | 9.6 | 7.943 | 12.6 | 6.9 | 15.2 | 29.7 | 3.1 | 42.5 | 29.37 | 60.271 | 1.4 | 0.0 | 1.99 | 222.751 | 170.047 | 5.594 | 23.8 |
| 503.bwaves_r | CPU | 4632.332 | 15.85 | 0.00 | 4.72 | 565.445 | 11.053 | 0.13 | 4.47 | 2.3 | 1.4 | 96.3 | 0.1 | 0.0 | 2.2 | 260.237 | 1.2 | 0.2 | 9.7 | 6.5 | 6.8 | 86.5 | 49.20 | 132.988 | 0.0 | 0.0 | 1.38 | 19.172 | 14.975 | 1.398 | 3.0 |
| 505.mcf_r | CPU | 706.488 | 15.73 | 0.00 | 15.39 | 1495.202 | 10.497 | 0.98 | 4.06 | 19.9 | 26.9 | 43.9 | 9.3 | 0.0 | 16.3 | 0.687 | 13.1 | 8.9 | 0.4 | 16.7 | 4.3 | 31.6 | 16.33 | 53.401 | 7.6 | 0.0 | 4.98 | 169.000 | 147.312 | 0.017 | 18.2 |
| 507.cactuBSSN_r | CPU | 609.922 | 15.69 | 0.00 | 495.30 | 1135.260 | 13.491 | 0.23 | 4.21 | 4.3 | 4.8 | 90.9 | 0.1 | 0.0 | 4.1 | 55.472 | 3.6 | 1.1 | 47.7 | 41.8 | 9.1 | 78.5 | 10.76 | 476.467 | 0.0 | 0.0 | 0.64 | 48.787 | 33.403 | 3.734 | 3.6 |
| 508.namd_r | CPU | 705.983 | 15.81 | 0.00 | 45.01 | 239.918 | 11.385 | 1.83 | 3.74 | 51.3 | 4.8 | 40.9 | 3.0 | 0.0 | 31.3 | 395.622 | 2.2 | 0.8 | 0.2 | 18.8 | 17.2 | 7.7 | 1.35 | 63.010 | 1.8 | 0.0 | 4.40 | 26.587 | 24.258 | 0.021 | 39.1 |
| 510.parest_r | CPU | 4550.517 | 15.80 | 0.00 | 16.88 | 213.125 | 10.974 | 0.29 | 4.41 | 5.8 | 4.2 | 89.7 | 0.3 | 0.0 | 4.8 | 338.504 | 1.9 | 1.6 | 1.4 | 23.3 | 6.8 | 67.4 | 34.77 | 93.116 | 0.2 | 0.0 | 1.59 | 106.362 | 90.964 | 3.249 | 17.3 |
| 511.povray_r | CPU | 1207.797 | 15.60 | 0.00 | 1449.68 | 63.683 | 10.402 | 1.81 | 3.78 | 52.4 | 6.6 | 38.9 | 2.1 | 0.3 | 31.4 | 244.832 | 2.5 | 1.5 | 3.7 | 20.9 | 11.2 | 12.4 | 0.06 | 63.187 | 1.1 | 0.2 | 0.25 | 157.689 | 109.665 | 10.900 | 39.5 |
| 519.lbm_r | CPU | 1416.599 | 15.53 | 0.00 | 7.13 | 256.969 | 10.588 | 0.26 | 4.42 | 4.7 | 2.1 | 93.2 | 0.0 | 0.0 | 4.5 | 51.354 | 1.1 | 1.0 | 15.3 | 6.0 | 2.2 | 88.9 | 24.72 | 172.647 | 0.0 | 0.0 | 0.08 | 138.203 | 137.728 | 0.026 | 2.3 |
| 520.omnetpp_r | CPU | 2024.583 | 15.83 | 0.00 | 870.95 | 107.720 | 9.994 | 0.28 | 4.58 | 5.6 | 9.6 | 81.9 | 3.0 | 0.0 | 4.9 | 16.375 | 4.4 | 3.9 | 2.3 | 28.4 | 4.8 | 66.7 | 44.62 | 72.990 | 2.5 | 0.1 | 3.02 | 196.963 | 143.767 | 11.785 | 12.8 |
| 521.wrf_r | CPU | 1953.561 | 15.79 | 0.00 | 1454.42 | 198.479 | 12.169 | 0.43 | 4.35 | 7.8 | 7.9 | 83.8 | 0.5 | 0.0 | 7.4 | 278.072 | 6.2 | 1.2 | 3.1 | 27.3 | 15.4 | 63.5 | 26.15 | 77.326 | 0.4 | 0.0 | 0.90 | 113.379 | 77.677 | 13.945 | 5.9 |
| 523.xalancbmk_r | CPU | 716.422 | 15.72 | 0.00 | 8293.00 | 930.346 | 10.489 | 0.77 | 4.32 | 19.0 | 8.9 | 71.1 | 0.9 | 0.1 | 12.2 | 34.341 | 3.6 | 2.2 | 4.0 | 20.7 | 3.0 | 42.9 | 15.96 | 75.229 | 0.5 | 0.1 | 0.34 | 267.659 | 234.583 | 7.449 | 35.4 |
| 525.x264_r | CPU | 427.195 | 15.00 | 0.00 | 16419.20 | 1583.996 | 12.872 | 1.59 | 3.69 | 38.0 | 21.0 | 38.6 | 2.5 | 0.1 | 27.2 | 189.560 | 11.2 | 3.9 | 28.6 | 42.4 | 11.4 | 16.3 | 6.16 | 37.180 | 1.8 | 0.0 | 2.76 | 66.296 | 48.490 | 3.845 | 28.0 |
| 526.blender_r | CPU | 1003.543 | 15.62 | 0.00 | 655.15 | 1981.576 | 11.564 | 1.08 | 3.88 | 24.9 | 6.6 | 62.3 | 6.2 | 0.0 | 17.9 | 397.608 | 3.7 | 1.1 | 1.0 | 28.3 | 13.6 | 31.2 | 15.56 | 31.225 | 4.5 | 0.0 | 2.09 | 134.627 | 120.414 | 1.256 | 28.1 |
| 527.cam4_r | CPU | 1312.508 | 15.81 | 7.50 | 935.89 | 3656.413 | 10.919 | 0.84 | 4.07 | 16.4 | 16.0 | 66.9 | 0.7 | 0.0 | 14.5 | 189.588 | 9.3 | 4.9 | 8.0 | 25.9 | 19.5 | 40.0 | 20.78 | 62.695 | 0.6 | 0.0 | 1.15 | 124.383 | 89.321 | 8.772 | 11.1 |
| 531.deepsjeng_r | CPU | 811.223 | 15.78 | 0.00 | 37.06 | 718.782 | 10.181 | 1.42 | 4.08 | 30.2 | 29.4 | 34.9 | 5.5 | 0.0 | 23.6 | 21.274 | 15.0 | 7.9 | 17.7 | 16.4 | 3.7 | 23.6 | 4.85 | 23.537 | 4.2 | 0.1 | 3.99 | 123.840 | 97.520 | 0.907 | 21.9 |
| 538.imagick_r | CPU | 371.223 | 14.33 | 0.00 | 1329.38 | 1026.201 | 10.757 | 2.19 | 3.63 | 56.0 | 11.1 | 25.2 | 7.7 | 0.0 | 33.8 | 149.855 | 3.8 | 2.9 | 0.1 | 14.4 | 8.3 | 6.9 | 6.13 | 11.978 | 4.6 | 0.0 | 0.89 | 182.276 | 175.161 | 0.187 | 39.6 |
| 541.leela_r | CPU | 1062.974 | 15.76 | 0.00 | 144.03 | 156.446 | 10.467 | 1.05 | 4.07 | 23.6 | 50.0 | 12.7 | 13.7 | 0.0 | 18.2 | 81.302 | 27.5 | 11.2 | 2.6 | 8.3 | 3.0 | 6.8 | 4.14 | 18.021 | 10.5 | 0.1 | 12.17 | 141.333 | 118.833 | 0.187 | 22.7 |
| 544.nab_r | CPU | 581.066 | 15.53 | 0.00 | 23.20 | 301.419 | 11.174 | 1.27 | 3.77 | 36.9 | 8.7 | 52.1 | 2.3 | 0.1 | 25.5 | 318.530 | 5.0 | 1.1 | 1.4 | 15.1 | 22.8 | 13.3 | 4.94 | 52.578 | 1.5 | 0.0 | 1.30 | 83.289 | 72.175 | 1.774 | 30.8 |
| 548.exchange2_r | CPU | 557.819 | 15.77 | 0.00 | 23.76 | 71.047 | 10.670 | 1.89 | 3.99 | 46.4 | 36.9 | 14.2 | 2.6 | 0.0 | 32.3 | 126.182 | 12.0 | 13.6 | 1.6 | 17.7 | 4.6 | 5.3 | 0.76 | 0.827 | 1.8 | 0.0 | 1.30 | 165.361 | 157.689 | 1.022 | 30.3 |
| 549.fotonik3d_r | CPU | 4829.371 | 15.91 | 0.00 | 32.94 | 144.718 | 11.510 | 0.11 | 4.54 | 2.0 | 1.9 | 96.1 | 0.1 | 0.0 | 1.9 | 286.386 | 1.3 | 0.5 | 6.8 | 12.8 | 2.7 | 91.8 | 44.60 | 137.645 | 0.0 | 0.0 | 0.45 | 36.518 | 33.907 | 0.471 | 1.7 |
| 554.roms_r | CPU | 2913.604 | 15.82 | 0.00 | 8.12 | 600.297 | 11.852 | 0.16 | 4.45 | 2.8 | 2.3 | 94.9 | 0.1 | 0.0 | 2.8 | 129.670 | 1.8 | 0.4 | 4.4 | 21.7 | 7.4 | 85.6 | 36.36 | 196.455 | 0.0 | 0.0 | 0.43 | 76.566 | 57.327 | 6.664 | 2.0 |
| 557.xz_r | CPU | 1413.262 | 15.76 | 0.00 | 11.48 | 1363.376 | 9.484 | 0.77 | 4.41 | 19.4 | 9.5 | 64.8 | 6.3 | 0.0 | 12.6 | 21.356 | 4.5 | 1.7 | 1.0 | 17.8 | 2.2 | 39.8 | 30.11 | 23.253 | 4.1 | 0.0 | 4.53 | 115.607 | 104.940 | 1.340 | 35.2 |
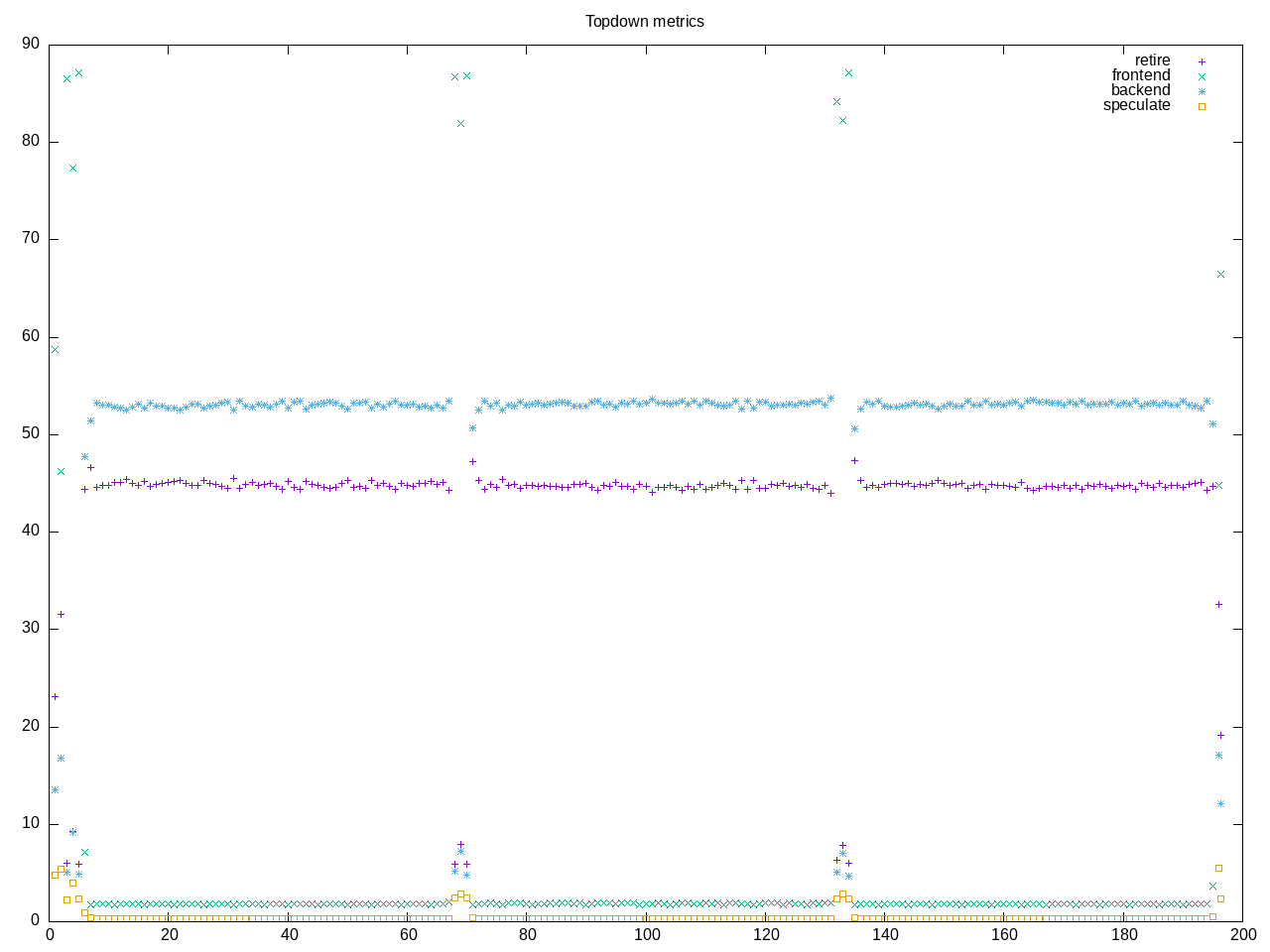
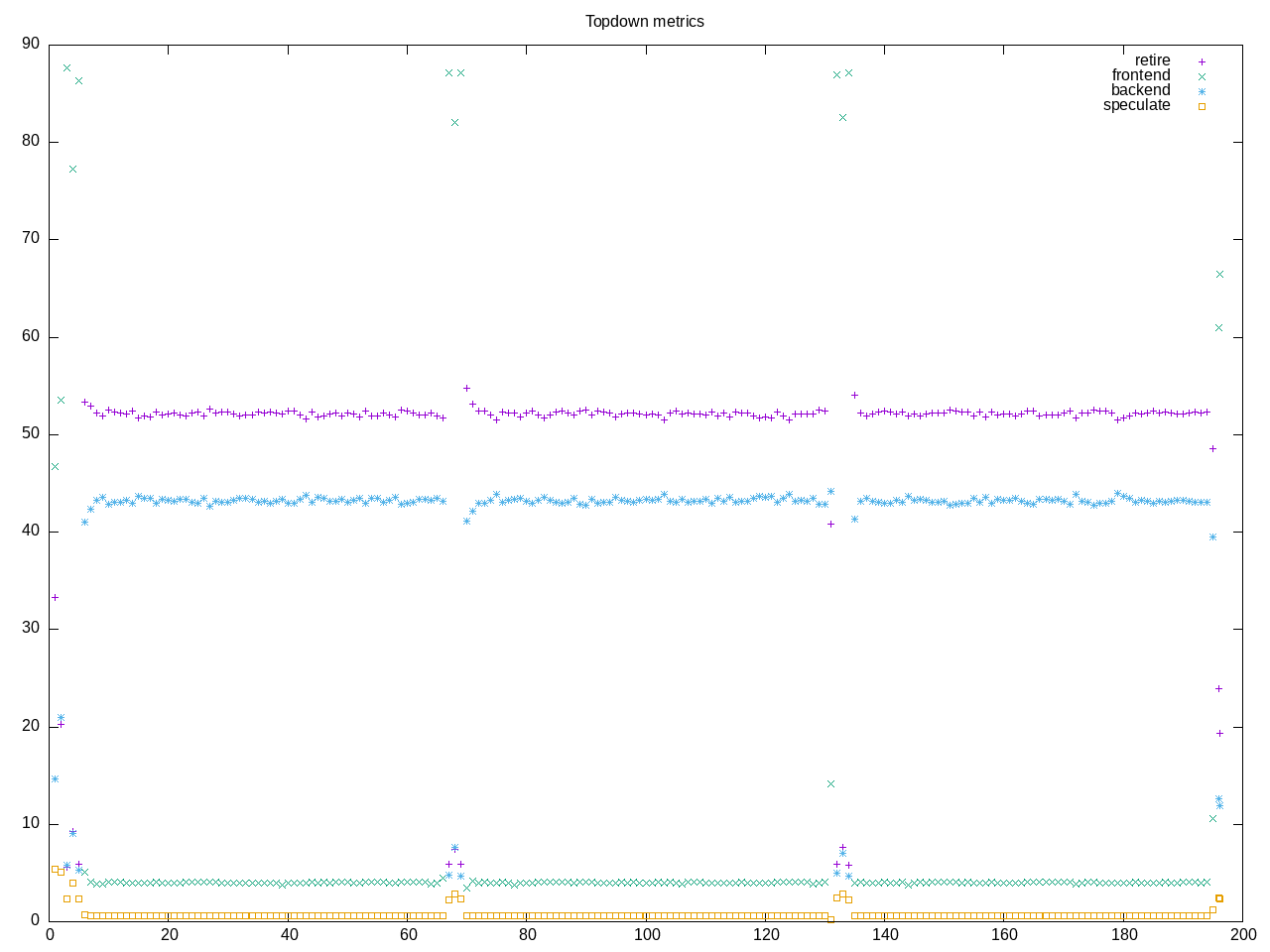
- The on_cpu values are high. This is very much a test of a CPU-dominated workload. There are not as many delays waiting for I/O, networking, graphics or other parts of the system. So there is an intensity to the mix that isn’t always as present with a more generic set of applications. Correspondingly the “GHz” values as a number of clock cycles per second are also high.
- Most of the floating point benchmarks are dominated by backend stalls. On my 7840 processor, the memory subsystem more often becomes a limiter.
I have gone through fprate and am in process of working through intrate. While I have run the intspeed and fpspeed benchmarks, those are lower on my list to characterize. This sets me up for two later exercises to follow (a) after zen5 processors are available, I can use the benchmarks to see how the workloads compare on a zen5 vs zen4 core and (b) I am thinking of a “clustering” exercise to look for similarities between both phoronix and SPEC CPU.