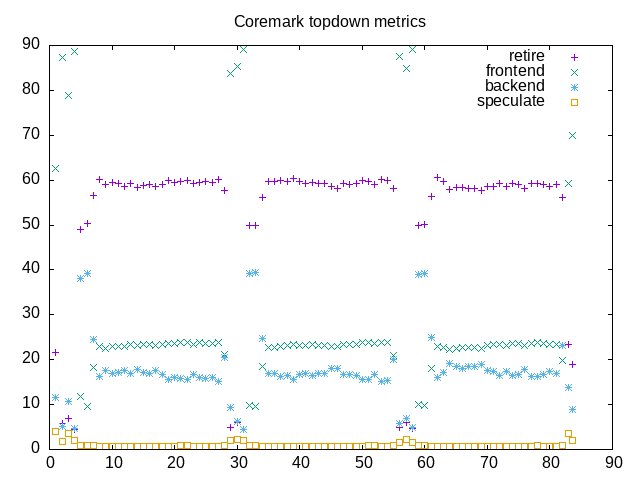
As a follow up comparison of Ryzen AI HX 370 processor compared to Ryzen 7840 HS, this posting looks at some Phoronix benchmarks.
I’ve run more than 200 Phoronix benchmarks in analysis using performance counters. I use these clusters to guide the benchmarks chosen trying to pick one from each cluster. In some cases where the benchmark didn’t easily run on Ubuntu 24.04, I skipped to another benchmark rather than debug the original issue. A cluster list from September 2024 below:
Cluster 0 (10 entries): 505.mcf_r 531.deepsjeng_r appleseed asmfish avifenc blender ospray primesieve stockfish v-ray
Cluster 1 (3 entries): 520.omnetpp_r amg compress-xz
Cluster 2 (7 entries): 500.perlbench_r 525.x264_r 544.nab_r brl-cad quicksilver smallpt vvenc
Cluster 3 (10 entries): aom-av1 cp2k neat openradioss qmcpack srsran svt-av1 vpxenc x264 x265
Cluster 4 (14 entries): 538.imagick_r 548.exchange2_r astcenc basis coremark cpuminer-opt kvazaar mrbayes quantlib rav1e rays1bench toybrot uvg266 webp2
Cluster 5 (10 entries): blake2 build-apache build-clash build-eigen octave-benchmark openjpeg selenium tscp tungsten vkpeak
Cluster 6 (19 entries): build2 build-ffmpeg build-gcc build-gdb build-gem5 build-godot build-linux-kernel build-llvm build-mesa build-mplayer build-nodejs build-\
wasmer hackbench helsing mnn rocksdb scylladb speedb stress-ng
Cluster 7 (5 entries): bork byte openscad phpbench sudokut
Cluster 8 (10 entries): aobench compress-lz4 crafty fhourstones git gnupg lammps lzbench tjbench webp
Cluster 9 (11 entries): apache-iotdb compress-zstd core-latency cpp-perf-bench draco encode-wavpack fftw jpegxl polybench-c polyhedron z3
Cluster 10 (10 entries): botan cachebench cryptsetup gcrypt glibc-bench gnuradio java-scimark2 nettle simdjson synthmark
Cluster 11 (7 entries): duckdb inkscape libreoffice node-web-tooling numpy perl-benchmark rsvg
Cluster 12 (15 entries): bullet compress-pbzip2 cython-bench encode-flac encode-mp3 encode-opus etcpak ffmpeg hmmer libraw node-octane pyperformance rnnoise scim\
ark2 stargate
Cluster 13 (7 entries): build-python compress-gzip compress-rar dacapobench gegl hadoop spark-tpcds
Cluster 14 (10 entries): 508.namd_r 511.povray_r aircrack-ng c-ray graphics-magick java-jmh namd povray rodinia svt-hevc
Cluster 15 (7 entries): askap hpcg incompact3d onnx parboil pytorch whisperfile
Cluster 16 (15 entries): 503.bwaves_r 507.cactuBSSN_r 510.parest_r 519.lbm_r 521.wrf_r 549.fotonik3d_r 554.roms_r cloverleaf easywave kripke mt-dgemm ncnn stream\
tensorflow xmrig
Cluster 17 (8 entries): darktable deepsparse ffte llama.cpp llamafile npb openfoam palabos
Cluster 18 (4 entries): 541.leela_r compress-7zip m-queens n-queens
Cluster 19 (7 entries): clomp deepspeech heffte himeno lulesh ngspice ramspeed
Cluster 20 (11 entries): 523.xalancbmk_r ai-benchmark libxsmm minibude oidn onednn openvino quadray tensorflow-lite xnnpack y-cruncher
Cluster 21 (4 entries): 502.gcc_r 527.cam4_r ebizzy faiss
Cluster 22 (5 entries): blosc dragonflydb mbw minife pjsip
Cluster 23 (4 entries): john-the-ripper openssl qe specfem3d
Cluster 24 (6 entries): arrayfire build-erlang build-imagemagick build-php nginx rbenchmark
Cluster 25 (11 entries): cryptopp dolfyn espeak gmpbench mpcbench mutex nwchem pybench securemark smhasher spark
Cluster 26 (12 entries): apache cassandra cockroach compilebench ctx-clock dbench fast-cli ipc-benchmark memcached pgbench sqlite wireguard
Cluster 27 (11 entries): clickhouse daphne dav1d gimp indigobench jpegxl-decode opencv pyhpc renaissance schbench svt-vp9
Cluster 28 (9 entries): 526.blender_r 557.xz_r embree graph500 lczero openvkl ospray-studio sysbench ttsiod-renderer
Cluster 29 (8 entries): financebench gpaw gromacs liquid-dsp pennant rawtherapee tnn whisper.cpp
Following is a summary of the benchmarks followed by some observations
| cluster | benchmark | metric ratio | 7840 metric | hx 370 metric | 7840 on cpu | hx 370 on cpu | 7840 retire | hx 370 retire | 7840 frontend | hx 370 frontend | 7840 backend | hx 370 backend | 7840 speculation | hx 370 speculation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ospray | 1.58 | 3.87314 / second | 6.07719 /sec | 14.46 | 21.28 | 29.3% | 30.7% | 27.3% | 11.8% | 41.1% | 54.2% | 2.3% | 2.4% |
| 1 | compress-xz | 0.96 | 28.665 seconds | 29.736 seconds | 11.04 | 12.45 | 8.2% | 7.3% | 10.2% | 17.3% | 76.5% | 68.2% | 5.1% | 7.1% |
| 2 | quicksilver | 1.41 | 12610000 fom | 1776333 fom | 15.38 | 19.9% | 49.8% | 15.9% | 6.9% | 15.9% | 38.9% | 59.5% | 4.4% | 2.7% |
| 3 | x265 | 1.65 | 13.79 frames/second | 22.81 frames/sec | 7.72 | 11.62 | 35.0% | 26.9% | 14.3% | 22.5% | 48.0% | 47.4% | 2.7% | 3.0% |
| 4 | coremark | 1.37 | 411227 iterations/sec | 561065 iterations/sec | 11.98 | 14.43 | 45.7% | 37.0% | 39.7% | 42.0% | 14.2% | 20.2% | 0.3% | 0.8% |
| 5 | build-eigen | 0.77 | 63.356 seconds | 82.516 seconds | 0.93 | 0.94 | 25.2% | 20.4% | 50.5% | 52.8% | 18.6% | 21.9% | 5.6% | 4.8% |
| 6 | build-gcc | 1.06 | 1038.166 seconds | 976.243 seconds | 9.98 | 10.91 | 24.1% | 18.3% | 51.5% | 60.0% | 19.7% | 18.2% | 4.7% | 3.1% |
| 7 | phpbench | 0.77 | 1159425 score | 900908 score | 0.80 | 0.83 | 61.2% | 48.6% | 23.0% | 30.1% | 15.0% | 20.1% | 0.8% | 1.1% |
| 8 | lzbench | 0.58 | 192 MB/s | 111 MB/s | 0.80 | 0.82 | 34.1% | 22.7% | 26.3% | 36.5% | 21.5% | 21.2% | 18.1% | 19.4% |
| 9 | compress-zstd | 1.01 | 1534.8 MB/s | 1556.6 MB/s | 4.23 | 3.45 | 21.4% | 18.3% | 9.5% | 17.8% | 62.8% | 55.7% | 6.3% | 0.2% |
| 10 | simdjson | 0.79 | 5.58 GB/s | 4.41 GB/s | 0.93 | 0.94 | 50.4% | 42.7% | 13.1% | 27.0% | 33.2% | 28.0% | 3.3% | 1.5% |
| 11 | perl-benchmark | 0.78 | 0.068363375 seconds | 0.08713901 seconds | 0.93 | 0.92 | 43.0% | 35.5% | 41.8% | 41.7% | 11.1% | 18.0% | 4.2% | 4.6% |
| 12 | ffmpeg | 0.99 | 252.66 fps | 251.11 fps | 3.67 | 2.61 | 32.3% | 29.1% | 18.4% | 30.3% | 29.0% | 33.8% | 5.6% | 6.7% |
| 13 | compress-gzip | 0.69 | 28.116 seconds | 40.597 seconds | 0.96 | 0.95 | 19.9% | 15.1% | 26.4% | 29.1% | 42.0% | 43.0% | 11.7% | 12.7% |
| 14 | povray | 1.34 | 38.681 seconds | 28.778 seconds | 13.32 | 18.83 | 31.8% | 40.1% | 3.5% | 16.3% | 25.5% | 41.5% | 1.3% | 2.0% |
| 15 | whisperfile | 1.11 | 54.13398 seconds | 48.57337 seconds | 7.44 | 10.81 | 20.0% | 15.2% | 2.2% | 15.5% | 77.3% | 68.9% | 0.3% | 0.3% |
| 16 | easywave | 1.26 | 8.809 seconds | 7.005 seconds | 14.60 | 20.53 | 4.5% | 4.8% | 3.1% | 15.1% | 83.6% | 74.6% | 0.1% | 0.1% |
| 17 | darktable | 1.34 | 5.711 seconds | 4.267 seconds | 3.42 | 5.50 | 27.9% | 19.1% | 7.2% | 15.2% | 63.5% | 60.9% | 1.3% | 1.0% |
| 18 | compress-7zip | 1.01 | 76676 MIPS | 77409 MIPS | 12.03 | 17.27 | 21.5% | 13.0% | 38.6% | 53.5% | 29.1% | 19.7% | 10.8% | 13.8% |
| 19 | himeno | 1.07 | 4447 MFLOPS | 4769 MFLOPS | 0.91 | 0.91 | 26.4% | 33.3% | 2.5% | 2.7% | 71.0% | 63.7% | 0.2% | 0.3% |
| 20 | minibude | 1.36 | 537.395 GFinst/s | 733.427 GFInst/s | 15.36 | 20.51 | 19.8% | 18.7% | 0.3% | 1.6% | 79.8% | 79.0% | 0.1% | 0.4% |
| 21 | ebizzy | 0.18 | 774839 records/s | 140179 records/s | 12.87 | 19.82 | 7.3% | 0.6% | 35.3% | 63.1% | 57.3% | 36.3% | 0.0% | 0.0% |
| 22 | pjsip | 0.79 | 4613 response/sec | 3665 response/sec | 2.40 | 2.23 | 12.2% | 11.3% | 38.4% | 33.9% | 48.4% | 51.3% | 1.1% | 1.1% |
| 23 | openssl | 1.63 | 15219867520 bytes/s | 17696663040 bytes/s | 15.51 | 23.25 | 46.5% | 33.4% | 4.9% | 13.3% | 48.7% | 53.2% | 0.0% | 0.0% |
| 24 | build-php | 1.16 | 67.052 seconds | 65.354 seconds | 8.30 | 10.20 | 20.8% | 15.1% | 50.4% | 57.0% | 24.8% | 24.1% | 3.9% | 3.4% |
| 25 | pybench | 0.84 | 554 ms | 663 ms | 0.75 | 0.79 | 70.1% | 63.9% | 15.9% | 17.0% | 11.4% | 17.0% | 2.6% | 2.1% |
| 26 | dbench | 3.74 | 687.037 MB/s | 2573 MB/s | 1.05 | 2.06 | 19.4% | 22.2% | 70.0% | 38.3% | 9.9% | 37.5% | 0.7% | 0.9% |
| 27 | indigobench | 1.40 | 2.090 samples/sec | 2.917 samples/sec | 14.14 | 21.25 | 25.8% | 19.9% | 14.8% | 29.3% | 54.0% | 44.9% | 5.4% | 5.4% |
| 28 | lczero | 1.41 | 108 nodes/sec | 152 nodes/sec | 13.23 | 18.34 | 16.8% | 14.3% | 4.4% | 3.8% | 78.7% | 81.6% | 0.1% | 0.1% |
| 29 | rawtherapee | 1.05 | 54.194 seconds | 51.600 seconds | 7.71 | 10.19 | 29.0% | 18.5% | 12.6% | 27.1% | 57.0% | 44.8% | 1.5% | 1.3% |
The first observation is most all single-threaded benchmarks run faster on the 7840 than on the Strix 370. In contrast the largest differences are among those with largest number of “on_cpu” threads.
There are two outliers that deserve a second look:
- ebizzy is over 5x faster on 7840 than hx 370. This benchmark runs quickly so need to make sure it is running correctly in both instances. I don’t see these ratios in the two SPEC CPU2017 benchmarks also part of this group.
- dbench runs over 3x faster on hx370 than 7840. The on_cpu is almost twice. Again useful to understand if there is another influence affecting this benchmark. Perhaps this one testing something else.